디스크 스토리지를 사용하고 있다면 웹 접속 정보와 서버 로그 문서가 모두 포함된 데이터 블록을 읽을 가능성이 큰데 이는 성능에 좋지 않은 영향을 끼칠 것이다(그림 6-3).
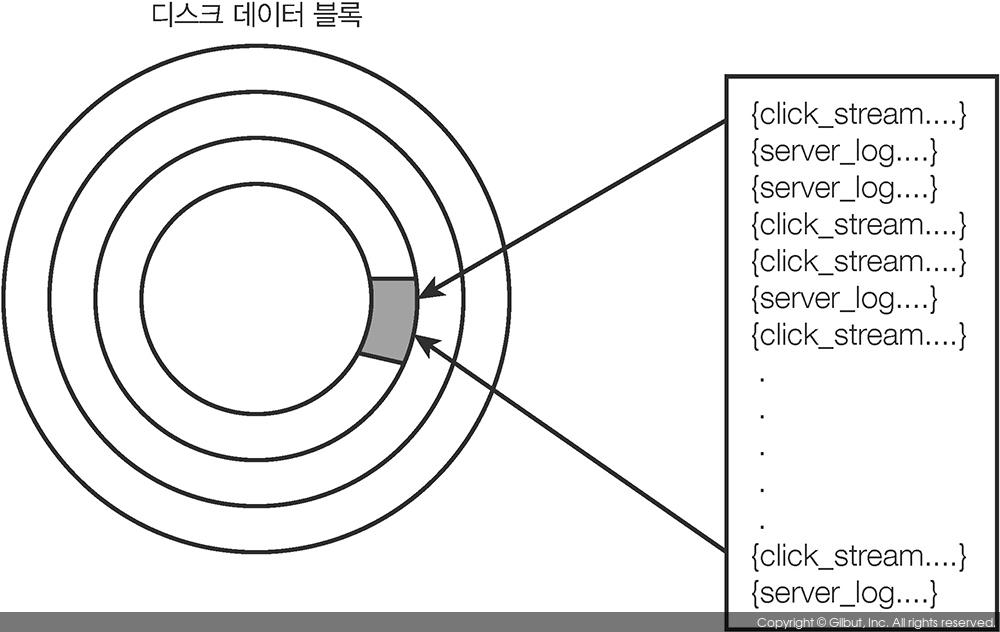
▲ 그림 6-3 문서 타입을 혼합하는 것은 디스크 데이터 블록 하나에 문서 타입 여러 개를 넣는 결과를 초래할 수 있다. 또한, 타입을 기준으로 특정 문서를 걸러내는 애플리케이션에서는 사용되지 않는 데이터까지 디스크에서 읽으므로 비효율적이다
성능을 향상시키는데 인덱스 사용을 주장할 수도 있다. 일부 경우에서 인덱스가 데이터 접근 성능을 향상시키는 것은 분명한 사실이다. 하지만 인덱스 자체도 메모리에 캐싱되거나 디스크에 저장될 것이고 디스크에서 인덱스를 읽는 것도 시간이 걸린다. 또한, 인덱스가 웹 접속 정보와 서버 로그 데이터 모두를 포함하고 있는 데이터 블록을 참조하고 있다면 애플리케이션에서는 한 가지 타입만 걸러내어 사용한다 하더라도 디스크에서 두 가지 타입 데이터를 모두 읽을 것이다.
컬렉션의 크기, 인덱스, 중복을 제거한 문서 고유의 개수(관계형 데이터베이스에서는 이를 카디널리티cardinality라고 한다)에 따라 인덱스를 사용하는 것보다 전체 문서 컬렉션을 스캔하는 것이 빠를 수 있다. 그리고 새로운 문서가 컬렉션에 추가될 때 인덱스를 생성하는 작업의 부하도 고려해야 한다.