엘보법(Elbow Method)
데이터 세트의 분산을 백분율로 계산하여 클러스터 개수에 대비한 차트로 그릴 수 있다. 클러스터가 최적인 지점이 있을 것이다. 클러스터 개수가 하나 늘어도 분류에 큰 변화가 없다면 그 점이 최적의 지점이다. 그림 8-4에서 클러스터가 4개일 때 데이터의 80%가 분류되므로 최적의 클러스터 개수는 4개임을 알 수 있다.
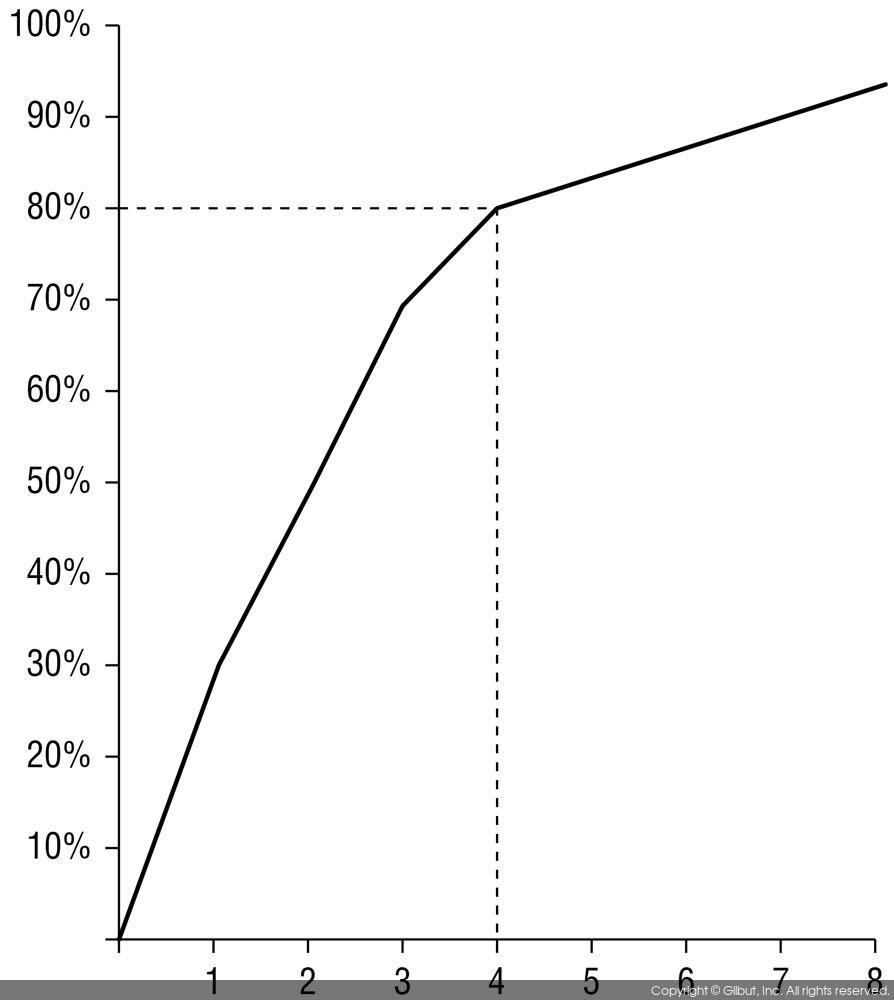
▲ 그림 8-4 엘보법 그래프
교차 유효성법(Cross-Validation Method)
데이터 세트를 몇 개로 분할하여 나눈 것을 가지고 순차적으로 분석해볼 수 있다. 제곱합 결과의 평균을 구해 클러스터 개수를 정한다.
웨카는 weka.clusterers.MakeDensity BasedClusterer 클래스로 교차 유효성법을 지원한다. 이 클래스는 이 장 후반부 실습 부분에서 명령줄 기반으로 상세히 다룬다.
실루엣법(Silhouette Method)
1986년 피터 루소(Peter J. Rousseeuw)가 처음 제안한 방법이다. 실루엣법은 클러스터 내 개체가 어디에 있는지 검증하는 방법을 제시한다.
어떤 개체가 같은 클러스터 안에 있는 다른 개체와 얼마나 유사한지를 계산할 수 있다. 클러스터에 연결된 개체의 평균을 구하고, 다른 클러스터와 얼마나 다른지 평가하여 평균 점수를 얻는다.
주요 목적은 클러스터 내 개체의 그룹화를 측정하는 것이다. 숫자가 낮을수록 좋다. 각각의 클러스터 평균을 비교하면 비슷할 것이다. 만약 실루엣이 매우 좁고 다른 클러스터의 실루엣보다 크다면 클러스터 수가 충분하지 않다는 것을 의미할 수도 있다.