5.4.4 맵리듀스
채널을 사용하여 맵리듀스 패턴을 구현해 보자.
맵리듀스는 대용량 데이터를 분산해서 빠르게 처리하려고 사용하는 프로그래밍 모델이다. 2014>년 구글이 분산 데이터 처리에 관한 논문 <MapReduce: Simplified Data Processing on Large Clusters>(http://research.google.com/archive/mapreduce.html)을 발표한 이후로 맵리듀스가 관심받기 시작했고, 하둡 프로젝트를 통해 널리 알려졌다. 이후 아마존에서 맵리듀스를 활용한 대량 데이터 처리 플랫폼 Amazon EMR(Amazon Elastic MapReduce)을 발표했고, 몽고DB나 CouchDB 같은 NoSQL에서도 맵리듀스 모델을 도입했다.
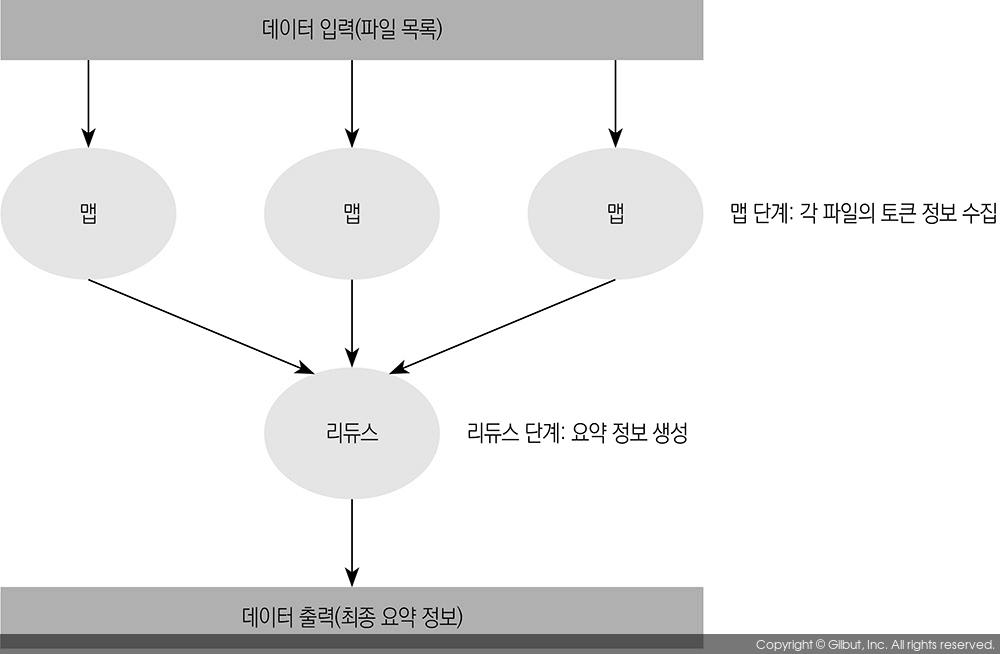
이번 절에서는 파일 목록 중에서 각 토큰이 파일별로 몇 번 사용됐는지 세는 프로그램을 맵리듀스 패턴으로 작성해 본다.
맵리듀스는 흩어져 있는 데이터 조각을 종류별로 모으는 맵(map) 단계와, 맵 작업으로 생성된 데이터를 모두 취합하여 원하는 형태의 최종 정보를 추출하는 리듀스(reduce) 단계로 나뉜다. 맵 단계에서는 파일 목록을 전달받아 각 파일의 토큰 정보를 수집하고, 리듀스 단계에서는 수집된 토큰 정보를 바탕으로 최종 요약 정보를 생성하는 작업을 하게 해보자.