BETTER WAY 3 반복 그룹을 제거하자
스프레드시트에서는 비슷한 데이터가 반복적으로 그룹을 이루는 것을 흔히 볼 수 있다. 정보 처리 작업자가 데이터베이스 정규화를 염두에 두지 않고 단순히 이런 데이터를 새 데이터베이스에 밀어 넣는 일도 다반사다. 그림 1-6은 데이터의 반복 그룹 예제다. 여기서는 DrawingNumber(도면 번호)가 Predecessor(선행 번호) 다섯 개와 관련되어 있다. 이 테이블은 도면 번호와 선행 번호 값 사이가 일대다(One-to-many) 관계다.
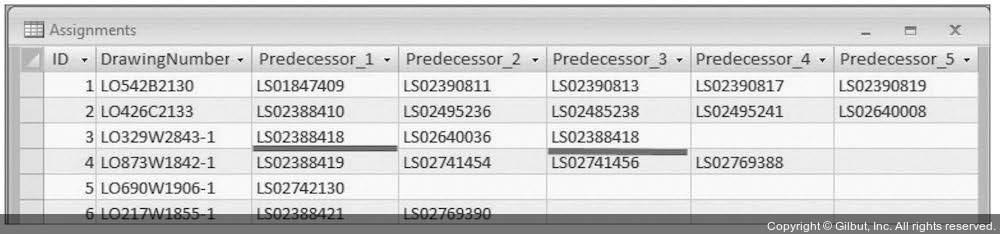
▲ 그림 1-6 단일 테이블에 있는 데이터의 반복 그룹
그림 1-6의 예제는 Predecessor란 단일 속성(Attribute)이 반복 그룹임을 보여 준다. 또 ID가 3인 레코드에는 의도하지 않은 중복 값이 들어 있다. 반복 그룹의 또 다른 예로 1월, 2월, 3월 등 월을 컬럼으로 하는 것을 들 수 있다. 하지만 반복 그룹이 단일 속성에만 국한되는 것은 아니다. 예를 들어 Quantity1, ItemDescription1, Price1, Quantity2, ItemDescription2, Price2, … QuantityN, ItemDescriptionN, PriceN이라는 컬럼이 있는 테이블을 보았다면, 이 역시 반복 그룹 패턴임을 알아챌 수 있어야 한다.