이전에 countplot()으로 시각화했던 정답값을 보면 해당 주제(IT과학, 생활문화)의 데이터가 다른 주제에 비해 빈도수가 적다. 유일 어절(unique_word_count)의 빈도값도 시각화해 보자.
sns.displot(data=df, x="unique_word_count", hue="topic", col="topic", col_wrap=2, aspect=5, height=2)
실행 결과
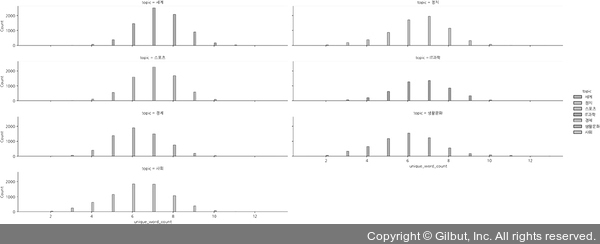
유일 어절의 시각화 작업은 중복을 제외한 데이터의 개수와 빈도를 한눈에 봄으로써 데이터에 대한 직관을 얻고 최종 결과도 짐작해 볼 수 있는 장점이 있다.