답변 여부(answered)에 대해 분류하기에는 표준편차가 너무 크고 모수가 적으므로, 투표수(votes)로 분석하겠다. 그 전에 답변 대상 데이터가 있는지 확인해 보자.
df.loc[df['answered'] == 1].shape
실행 결과
(0, 8)
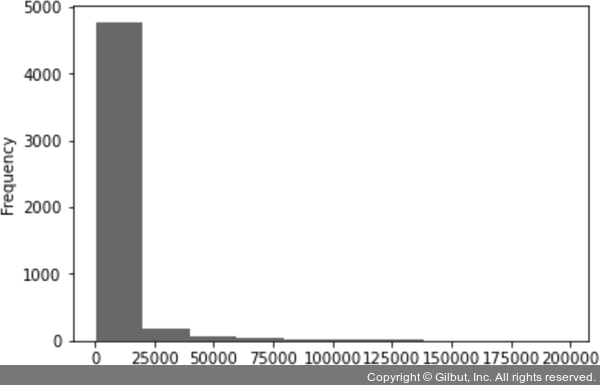
20만 건 이상 투표한 데이터는 모두 제외했으므로, votes에서 답변 대상인 건은 0으로 잘 출력된다. 이제 도수 분포표를 시각화한 히스토그램(histogram)을 그려서 데이터의 분포를 확인해 보자.
%matplotlib inline
df['votes'].plot.hist()
실행 결과