RNN으로 텍스트를 분류하기 위해서는 먼저 입출력의 개수에 따른 구분과 타임 스텝으로 이야기되는, 전후 문장의 의존성이 어떻게 연산되는지를 이해해야 한다. RNN은 입출력 개수에 따라 일대일, 일대다, 다대일, 다대다로 구분된다.7
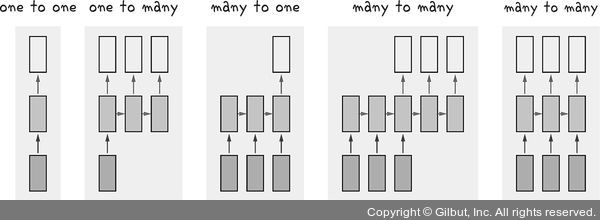
그림 7-6 | 일대일, 일대다, 다대일, 다대다 8
데이터에 종류에 따라서는 다음과 같이 구분할 수 있다.
• 일대일(one to one): 기본 모델
• 일대다(one to many): 하나의 이미지를 여러 문장으로 표현 등
• 다대일(many to one): 영화 리뷰를 긍정 또는 부정으로 감정 분류 등
• 다대다(many to many): 여러 단어를 입력받아 여러 단어로 구성된 문장을 반환하는 번역기 등