return_sequences=True를 선택하면 메모리 셀이 모든 시점(time step)에 대해서 은닉 상태값을 출력하며, return_sequences=False이면 메모리 셀은 하나의 은닉 상태값만 출력한다. 즉, 마지막 시점(time step)의 메모리 셀의 은닉 상태값만 출력하게 된다. 그렇기 때문에 Dense 층 바로 위 Bidirectional LSTM은 return_sequences를 설정하지 않았다.
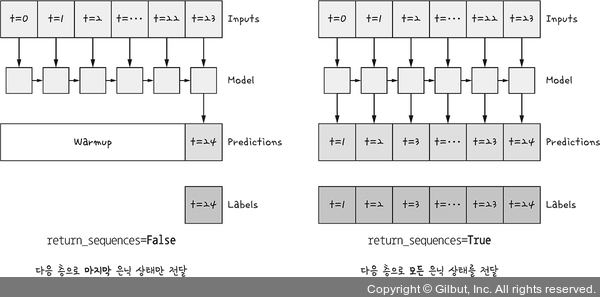
그림 7-8 | return_sequences12
기울기 소실은 안정적으로 하강하는 것이 아니라 구불구불한 길을 내려오는 것과 같은데, 기울기가 너무 크거나 작은 곳에서 학습되지 않는 문제를 막기 위해 BatchNormalization으로 정규화해 준다. 다음으로 Dense로 은닉층을 구성하고 마지막으로 Dense 출력층을 클래스 개수로 적용해 주었고 활성화 함수는 relu와 softmax를 사용했다.