TIP
이해를 돕기 위해 케라스 사이트에서 Dense 12, input 8차원을 적용한 이미지를 소개한다.
# 다음 코드는 이해를 돕기 위한 Dense 12, input 8차원의 예다.
model = Sequential()
model.add(Dense(12, input_dim=8, init='uniform', activation='relu'))
model.add(Dense(8, init='uniform', activation='relu'))
model.add(Dense(1, init='uniform', activation='sigmoid'))
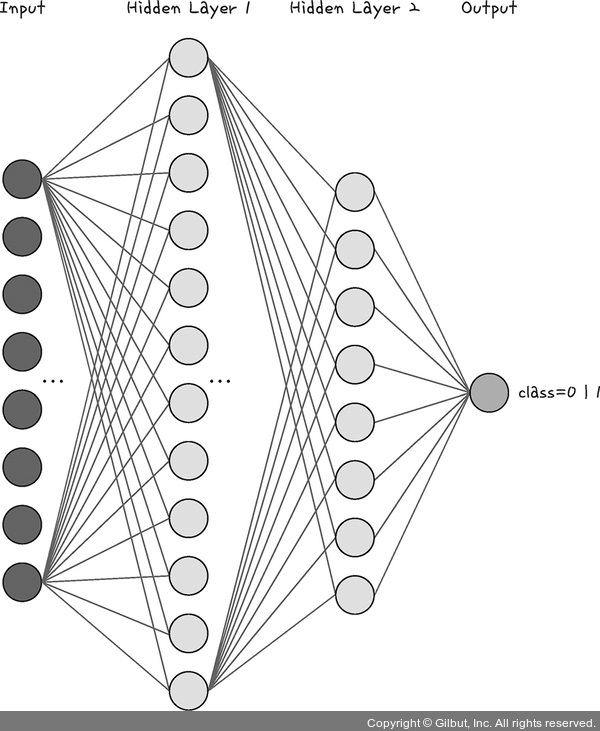
그림 7-9 | 케라스 신경망 시각화13