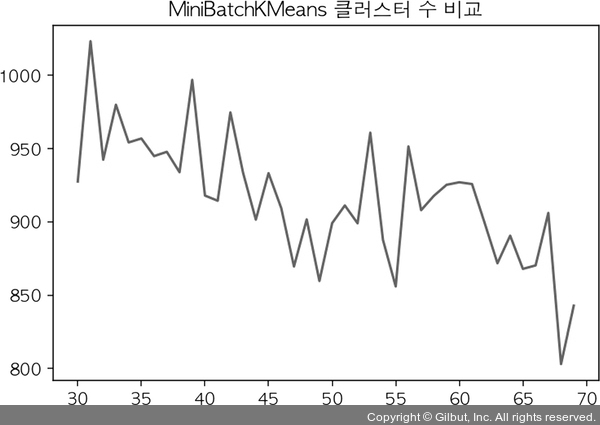
위에서 구한 값을 시각화해 보자. x축에는 클러스터의 수를, y축에는 b_inertia 값을 넣어 그린다.
plt.plot(range(start, end), b_inertia) plt.title("MiniBatchKMeans 클러스터 수 비교")
Text(0.5, 1.0, 'MiniBatchKMeans 클러스터 수 비교')