그림 8-2 | 실루엣 계수의 이상적인 군집
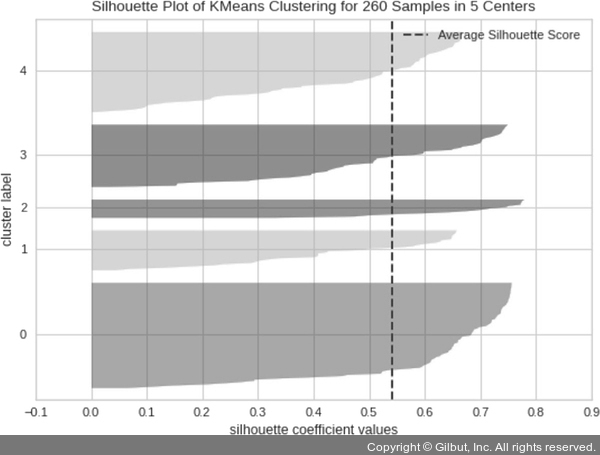
이벤트 텍스트로 군집화한 실루엣 계수를 확인해 보자.
from yellowbrick.cluster import SilhouetteVisualizer visualizer = SilhouetteVisualizer(mkmeans, colors='yellowbrick') visualizer.fit(feature_tfidf.toarray()) visualizer.show()