close
더북(TheBook)
search
모두의 한국어 텍스트 분석 with 파이썬
더북(TheBook)
home
Home
1장 코랩 시작하기
LESSON OT 들어가며
LESSON 01 코랩 실행하기
1 주석
2 단축키
LESSON 02 코랩에서 실습 코드 열기
1 코랩 테마
2장 파이썬에서 문자열 다루기
LESSON OT 들어가며
LESSON 01 문자열 실습 전에
LESSON 02 문자열 실습
1 문자열 표현
2 오류 처리
3 표현 방법 + 오류 처리
LESSON 03 문자열을 다루는 여러 방법
1 변수
2 인덱싱
3 슬라이싱
4 문자열의 길이, 단어 수
5 문자열 함수
6 반복
7 함수
8 문자열 내장 메서드 목록
3장 라이브러리 다루기
LESSON OT 들어가며
LESSON 01 판다스
1 데이터 프레임과 시리즈 이해하기
2 str 접근자로 문자열 다루기
LESSON 02 넘파이
1 넘파이 배열 이해하기
2 맷플롯립으로 넘파이 배열 시각화하기
4장 단어 가방 모형과 TF-IDF
LESSON OT 들어가며
LESSON 01 단어 가방 모형
1 단어 가방 모형을 만드는 방법
2 단어 가방 모형 만들기
3 n-gram: 앞뒤 단어 묶어서 사용
4 min_df와 max_df: 빈도수 설정
5 max_features: 학습 단어 개수 제한
6 stop_words: 불용어 제거
7 analyzer: 문자, 단어 단위 설정
LESSON 02 TF-IDF
1 TF-IDF 가중치를 적용하는 방법
5장 연합뉴스 타이틀 주제 분류
LESSON OT 들어가며
LESSON 01 데이터 선택하기
LESSON 02 분류 과정
LESSON 03 분류를 위한 기본 설정
1 라이브러리 불러오기
2 시각화를 위한 폰트 설정
LESSON 04 데이터 불러오기
LESSON 05 데이터 전처리하기
1 데이터 전처리를 위한 데이터 병합
2 정답값 빈도수 확인
3 문자 길이 확인
4 맷플롯립과 시본을 이용해 히스토그램으로 시각화
5 주제별 글자와 단어의 빈도 확인
LESSON 06 문자 전처리하기
1 숫자 제거
2 영문자는 모두 소문자로 변경
3 형태소 분석기로 조사, 어미, 구두점 제거
4 불용어 제거
LESSON 07 학습, 시험 데이터 세트 분리하기
LESSON 08 단어 벡터화하기
LESSON 09 학습과 예측하기
1 랜덤 포레스트 분류기
2 교차 검증
3 학습
LESSON 10 답안지 불러오기
6장 국민청원 데이터 시각화와 분류
LESSON OT 들어가며
LESSON 01 분석 과정
LESSON 02 분석을 위한 기본 설정
1 라이브러리 불러오기
LESSON 03 판다스로 데이터 불러오기
1 구글 드라이브에 파일 다운로드
2 다운로드한 데이터 살펴보기
3 결측치가 있는지 확인하기
LESSON 04 판다스 데이터 분석과 시각화
1 답변 대상 청원 열 추가
2 청원 기간별 분석
3 청원 기간과 분야별 분석
4 시각화
LESSON 05 soynlp로 워드클라우드 그리기
1 라이브러리와 데이터
2 토큰화
3 텍스트 데이터 전처리
4 워드클라우드 그리기
5 명사만 추출해 시각화
LESSON 06 머신러닝으로 국민청원 데이터 이진 분류하기
1 지도학습과 데이터 세트 분리
2 이진 분류 대상 정하기
3 평균을 기준으로 투표수 예측하기
4 전처리하기
5 학습 세트와 시험 세트 만들기
6 단어 벡터화하기
7 TF-IDF 가중치 적용하기
8 LightGBM으로 학습시키기
9 평가하기
10 예측하기
11 예측 결과의 정확도 평가하기
7장 ‘120다산콜재단’ 토픽 모델링과 RNN, LSTM
LESSON OT 들어가며
LESSON 01 분석 과정
LESSON 02 잠재 디리클레 할당으로 토픽 분류하기
1 라이브러리 설치 및 데이터 불러오기
2 단어 벡터화하기
3 잠재 디리클레 할당 적용하기
4 pyLDAvis를 통한 시각화하기
5 유사도 분석하기
LESSON 03 순환 신경망으로 텍스트 분류하기
1 라이브러리와 데이터 불러오기
2 학습/시험 데이터 세트 분리하기
3 레이블값을 행렬 형태로 만들기
4 벡터화하기
5 패딩하기
LESSON 04 모델 만들기
1 Bidirectional LSTM
2 모델 컴파일하기
3 학습하기
4 예측하기
5 평가하기
8장 인프런 이벤트 댓글 분석
LESSON OT 들어가며
LESSON 01 분석 과정
LESSON 02 분석을 위한 기본 설정
1 라이브러리 불러오기
2 데이터 불러오기
LESSON 03 데이터 전처리
1 중복된 글 제거하기
2 소문자로 변환하기
LESSON 04 문자열 분리로 ‘관심강의’ 분리하기
LESSON 05 벡터화하기
LESSON 06 TF-IDF로 가중치를 주어 벡터화하기
LESSON 07 군집화하기
1 KMeans
2 MiniBatchKMeans
3 클러스터 예측 평가하기
4 실루엣 계수 분석하기
9장 ChatGPT를 사용한 문장 생성 자동화
LESSON OT 들어가며
LESSON 01 생성 모델의 개념
LESSON 02 생성 모델의 파라미터 크기와 종류
LESSON 03 ChatGPT 사용하기
LESSON 04 한국어 생성 서비스: 뤼튼
LESSON 01
생성 모델의 개념
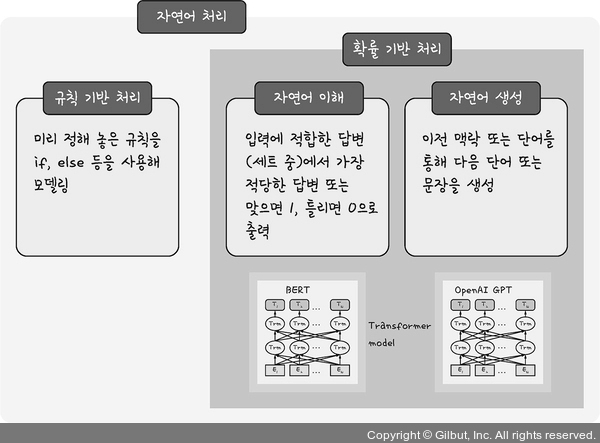
딥러닝을 연구하는 분야에서는 오랫동안 자연어 이해와 자연어 생성을 구분하려는 흐름이 있었고 이는 모델 발전에도 영향을 미쳤다.
그림 9-2
| 자연어 처리 세분화
다음으로 공부할 책 추천
Prev
BUY
Next
신간 소식 구독하기
뉴스레터에 가입하시고 이메일로 신간 소식을 받아 보세요.
Email address