그리고 preprocess_data 함수를 각 데이터 세트에 적용합니다(②). num_parallel_calls=AUTOTUNE은 병렬 처리를 최적화합니다. shuffle(buffer_size=1024)는 데이터 세트의 항목을 무작위로 섞어, 모델이 일반화될 수 있도록 돕습니다. buffer_size는 셔플을 위한 버퍼의 사이즈를 지정합니다. prefetch(buffer_size=1024)는 훈련 중에 데이터 로딩 시간을 줄이기 위해 다음 배치를 미리 로드하고 준비합니다. 이는 CPU와 GPU가 동시에 작업을 수행할 수 있게 하여, 데이터 로딩으로 인한 대기 시간을 최소화합니다.
이러한 파이프라인 설정은 모델 학습 과정의 효율성과 성능을 향상시킵니다.
이제 모델 부분을 작성해보겠습니다. 모델은 다음과 같은 FCN 논문의 네트워크를 그대로 따라갈 예정입니다.
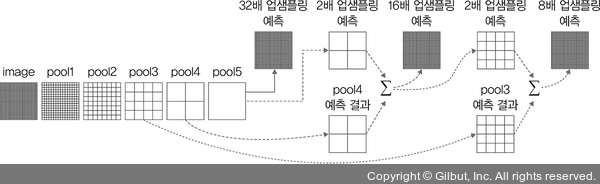
▲ 그림 5-37 FCN 전체 구조