모델 아키텍처
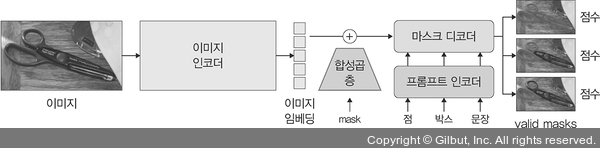
▲ 그림 5-46 SAM 아키텍처
SAM은 이미지 인코더, 프롬프트 인코더, 마스크 디코더로 구성됩니다. 이미지 인코더는 이미지의 임베딩을 계산하고, 프롬프트 인코더는 프롬프트를 임베딩합니다. 이 두 정보는 마스크 디코더에서 결합되어 분할 마스크를 예측합니다. 여기서 이미지 인코더는 사전 학습된 VIT를 사용하게 됩니다. 이미지 인코딩 과정에 MAE(Masked Autoencoder)로 사전 훈련된 ViT(Vision Transformer)를 사용합니다. 이 선택은 ViT의 이미 입증된 우수성에 기반한 것으로, 별도의 깊은 논의 없이도 그 타당성을 인정할 수 있습니다.