LLM을 개발하는 일반적인 과정은 사전 훈련과 미세 튜닝으로 구성됩니다. 사전 훈련의 ‘사전’은 LLM 같은 모델을 다양한 대규모 데이터셋에서 훈련시켜 언어에 대한 폭넓은 이해를 쌓는 초기 단계를 의미합니다. 이렇게 사전 훈련된 모델을 파운데이션 모델(foundation model)로 사용하여 미세 튜닝을 통해 더 개선할 수 있습니다. 미세 튜닝은 모델을 구체적인 작업이나 도메인을 위한 특정 데이터셋에서 훈련하는 과정입니다. 사전 훈련과 미세 튜닝으로 구성된 두 단계 훈련 방식이 그림 1-3에 나타나 있습니다.
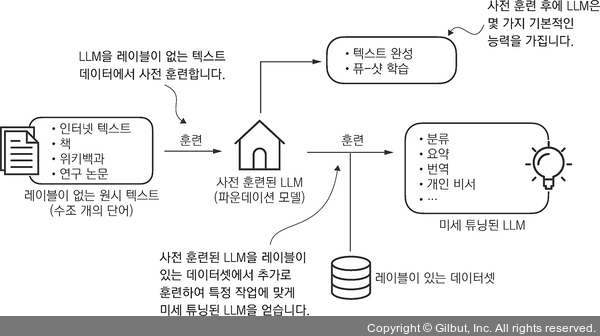
▲ 그림 1-3 사전 훈련은 대규모 텍스트 데이터셋에서 다음 단어 예측으로 수행됩니다. 그런 다음 사전 훈련된 LLM을 레이블이 있는 작은 데이터셋에서 미세 튜닝할 수 있습니다.