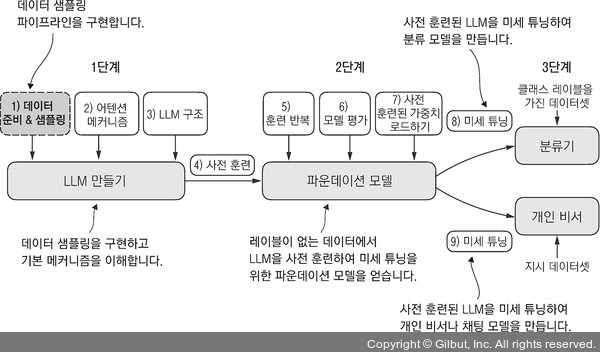
▲ 그림 2-1 LLM 구현을 위한 3개의 주요 단계. 이 장은 1단계의 첫 번째 스텝인 데이터 샘플링 파이프라인(pipeline)에 초점을 맞춥니다.
LLM을 훈련하기 위해 입력 텍스트를 준비하는 방법을 배우겠습니다. 여기에는 텍스트를 개별 단어와 부분단어 토큰으로 분할하는 작업이 포함됩니다. 그런 다음 LLM을 위해 벡터 표현으로 인코딩할 수 있습니다. GPT처럼 인기 있는 LLM에서 사용하는 바이트 페어 인코딩과 같은 고급 토큰화 방법에 대해서도 배우겠습니다. 마지막으로 샘플링과 데이터 로드 전략을 구현하여 LLM 훈련에 필요한 입력-출력 쌍을 생성하겠습니다.