SECTION 2.6 슬라이딩 윈도로 데이터 샘플링하기
LLM을 위한 임베딩을 만드는 다음 단계는 LLM 훈련에 필요한 입력-타깃 쌍을 생성하는 것입니다. 이런 입력-타깃 쌍이 어떻게 구성될까요? 앞서 배웠듯이 그림 2-12처럼 LLM은 텍스트에 있는 다음 단어를 예측하는 식으로 사전 훈련됩니다.
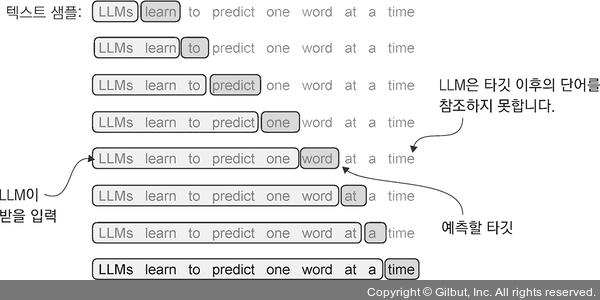
▲ 그림 2-12 텍스트 샘플이 주어지면 LLM의 입력으로 제공할 부분 샘플을 위해 입력 블록을 추출합니다. 훈련 과정에서 LLM의 예측 작업은 입력 블록 다음에 오는 단어를 예측하는 것입니다. 훈련하는 동안 타깃 이후의 모든 단어를 마스킹(masking)합니다. 이 그림에 나타난 텍스트는 LLM이 처리하기 전에 토큰화를 거쳐야 하지만 그림을 이해하기 쉽도록 토큰화 단계를 생략했습니다.