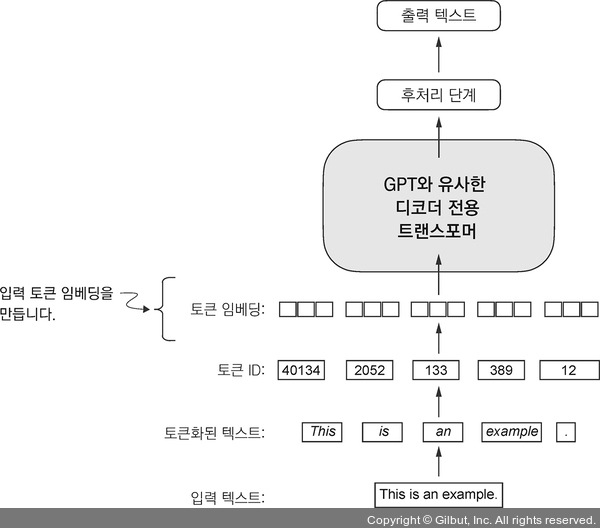
▲ 그림 2-15 준비 과정에는 텍스트를 토큰화하고, 텍스트 토큰을 토큰 ID로 바꾸고, 토큰 ID를 임베딩 벡터로 바꾸는 작업이 포함됩니다. 이 절에서는 앞서 생성한 토큰 ID를 사용해 토큰 임베딩 벡터를 만듭니다.
GPT와 같은 LLM은 역전파(backpropagation) 알고리즘으로 훈련되는 심층 신경망이므로 연속적인 벡터 표현인 임베딩이 필수적입니다.
NOTE
역전파로 신경망을 훈련하는 방법에 대해 궁금하다면 부록 A의 A.4절을 참고하세요.