이러한 모델들은 서로 다른 크기의 필터, 깊은 네트워크, 스킵 연결과 같은 혁신적인 아이디어를 통해 복잡한 이미지 데이터도 효과적으로 처리할 수 있음을 입증했습니다. 또한 이러한 네트워크 구조들을 기반으로 DenseNet, Xception, EfficientNet, YOLO 등 다양한 변형 모델이 등장하면서 연산 효율성, 파라미터 수, 모델 크기 간 균형을 맞춘 최적화 방안이 꾸준히 제안되었습니다.
YOLO(You Only Look Once)는 실시간 객체 검출을 위한 딥러닝 모델로, 이미지를 한 번의 네트워크 통과로 처리해 객체의 위치(bounding box)와 클래스(label)를 동시에 예측합니다. 또한, 이미지를 여러 격자(grid)로 나누고 각 격자에서 객체가 있을 확률과 위치를 한 번에 예측합니다. 이러한 방식은 객체를 반복해서 탐색하지 않고 한 번의 처리로 모든 객체를 예측하도록 설계되었습니다. 덕분에 객체 검출을 빠르게 실시간으로 수행할 수 있었습니다.
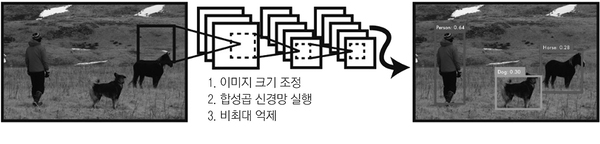
▲ 그림 1-30 YOLO 객체 검출
출처: https://encord.com/blog/yolo-object-detection-guide/