GRU는 LSTM에 비해 파라미터 수가 적고 계산 효율성이 높아, 학습 속도가 빠르고 구현이 간단합니다. 성능 면에서도 많은 경우 LSTM에 필적하거나 더 나은 결과를 보여 다양한 시퀀스 처리 문제에서 널리 사용하고 있습니다.
RNN에서 시작해 LSTM, GRU로 이어지는 순환 신경망의 발전 과정은 딥러닝이 긴 시퀀스 의존성 문제를 어떻게 구조적 개선과 실험적 검증을 통해 해결했는지를 잘 보여줍니다. 이러한 발전을 통해 자연어 처리, 음성 인식, 시계열 분석 등 시퀀스 데이터가 중요한 다양한 분야에서 딥러닝 모델의 성능과 안정성이 크게 향상되었습니다. 특히 LSTM과 GRU는 어텐션과 트랜스포머가 등장하기 전까지 시퀀스 처리 분야의 주력 모델로 활용되었습니다.
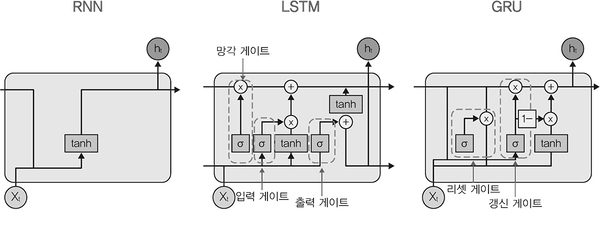
▲ 그림 1-44 RNN, LSTM, GRU 구조