BERT의 사전 학습 방법은 MLM(Masked Language Model)과 NSP(Next Sentence Prediction)입니다. MLM은 입력 문장에서 랜덤하게 일부 단어를 마스크하고, 해당 단어를 예측하는 학습 방법입니다. NSP는 두 문장이 주어졌을 때 두 번째 문장이 첫 번째 문장의 다음 문장인지 아닌지를 예측하는 것으로 학습합니다. 이를 통해 모델은 문장과 문맥의 의미를 파악할 수 있습니다.
T5는 텍스트를 입력(NLU, 자연어 이해)과 출력(NLG, 자연어 생성) 모두에서 동일한 텍스트 형식으로 처리하는 ‘텍스트-투-텍스트(Text-to-Text)’ 접근 방식의 자연어 처리 모델입니다. 트랜스포머 인코더-디코더를 모두 사용합니다. 또한, 대량의 언어 데이터인 C4(Colossal Clean Crawled Corpus, 웹 사이트에서 스크랩된 수백 기가의 정제된 영어 텍스트 데이터셋)를 사전 훈련해 번역, 요약, 질의응답 등 다양한 자연어 처리 작업을 효과적으로 수행할 수 있습니다. T5는 텍스트 이해 작업뿐만 아니라 텍스트 생성 작업에서도 유용합니다.
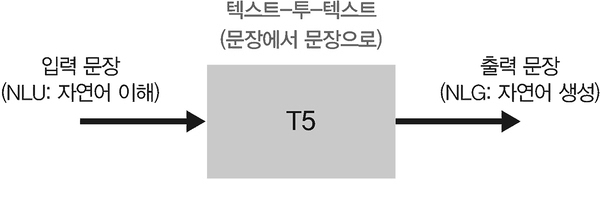
▲ 그림 2-22 T5 구조