MoE는 여러 개의 전문가 모델 중 입력에 맞는 일부만 활성화하여 계산 효율을 높이는 신경망 구조입니다. 이를 통해 모델 크기는 커지지만 연산 비용은 줄일 수 있어 성능 향상과 효율성을 동시에 달성할 수 있습니다.
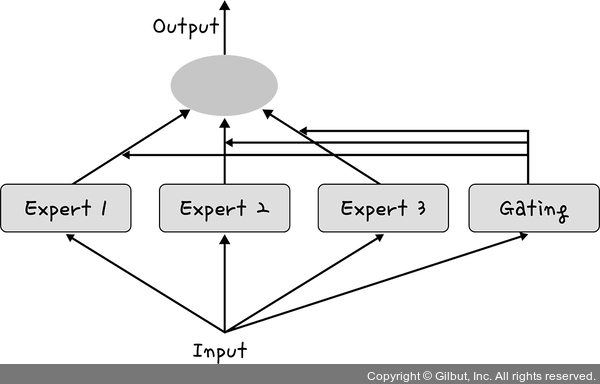
▲ 그림 3-8 Mixture of Experts 아키텍처
경량화된 모델
DeepSeek는 OpenAI의 GPT-4o 같은 대형 모델보다 경량화된 구조를 갖추고 있습니다. 이를 위해 다음과 같은 기술이 사용됩니다.
MoE는 여러 개의 전문가 모델 중 입력에 맞는 일부만 활성화하여 계산 효율을 높이는 신경망 구조입니다. 이를 통해 모델 크기는 커지지만 연산 비용은 줄일 수 있어 성능 향상과 효율성을 동시에 달성할 수 있습니다.
▲ 그림 3-8 Mixture of Experts 아키텍처
경량화된 모델
DeepSeek는 OpenAI의 GPT-4o 같은 대형 모델보다 경량화된 구조를 갖추고 있습니다. 이를 위해 다음과 같은 기술이 사용됩니다.