8.1.3 부분 문자열의 빈도를 구하는 count( )
문서를 편집할 때 어떤 단어를 과하게 반복 사용했는지 알 수 있다면 좋을 것이다. 간단한 글을 썼는데 첫 문단에서 ‘그래서’라는 단어를 다섯 번이나 사용했다는 사실을 발견했다고 하자. 글 전체를 읽으면서 직접 그 단어를 세어 보는 대신 글 본문을 문자열로 만들고 그 문자열에 연산을 사용해 "그래서"라는 부분 문자열이 얼마나 들어 있는지 자동으로 세어주는 프로그램을 작성할 수 있다.
count()를 사용하면 부분 문자열이 몇 번 나타나는지 세는 프로그램을 만들 수 있다. count()는 정수를 돌려준다. 예를 들어 fruit = "banana"라면 fruit.count("an")는 2로 계산된다. count()에서 알아둬야 할 중요한 점이 하나 있다. count()는 부분 문자열이 서로 겹치는 경우를 처리하지 못한다. 예를 들어 fruit.count("ana")의 결과는 1이다. "ana"가 두 번 들어 있기는 하지만 "a"가 중간에 겹치기 때문이다. 그림 8-2처럼 말이다.
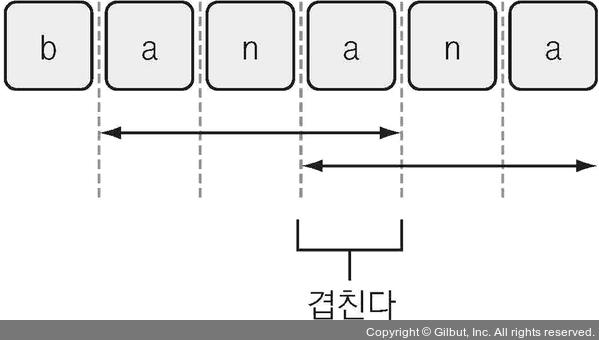
▲ 그림 8-2 “banana” 문자열에서 “ana”가 등장하는 횟수 세기. 결과는 1인데 두 “ana” 사이에 같은 위치에 있는 “a”가 두 번 등장하기 때문이다. 파이썬 count() 명령은 이런 경우를 염두에 두고 만들어지지 않았다
![]() 셀프 체크 8.3
셀프 체크 8.3
a = "python 4 ever&EVERRRR"일 때 다음 식을 계산한 결과는 무엇일까? 생각한 대로 결과가 나오는지 스파이더에서 직접 실행해 보자.
1. a.count("ev")
2. a.count(" ")
3. a.count(" 4 ")
4. a.count("eVer")
5. a.count("RR")