

















그림 1-14의 petal_length는 다봉분포(bimodal distribution)를 보인다. 분명 특정 붓꽃의 꽃잎이 다른 품종보다 더 짧을 것이다. 데이터를 상자차트(boxplot)로도 그릴 수 있다. 상자차트는 데이터 과학자가 데이터 분포를 파악할 때 주로 사용하는 시각화 방식으로, 제1사분위수(first quartile), 중앙값(median), 제3사분위수(third quartile)를 사용해 그린다.
df.plot.box(title='Boxplot of Sepal Length & Width, and Petal Length & Width')
plt.show()
상자차트를 그린 결과는 다음 그림 1-15와 같다.
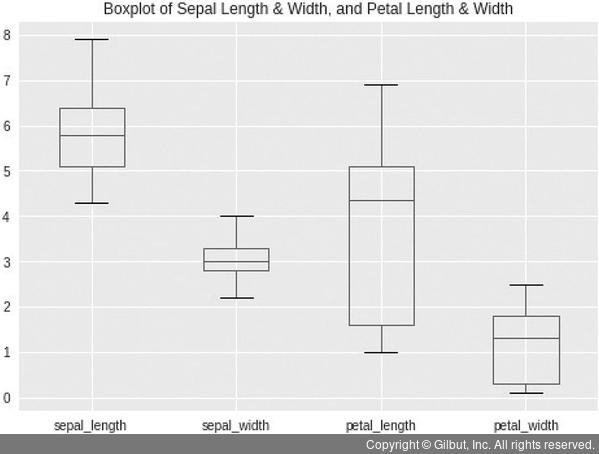
▲ 그림 1-15 붓꽃 데이터셋으로 그린 상자차트
그림에서 볼 수 있듯이 sepal_width의 분산이 다른 숫자 변수보다 훨씬 더 작고, petal_length의 분산이 가장 크다.
지금까지 판다스로 손쉽게 데이터를 시각화하는 방법을 살펴봤다. 재차 강조하지만, 머신 러닝 워크플로에서 가장 중요한 단계는 탐색적 데이터 분석이다. 책의 나머지 프로젝트에서도 탐색적 데이터 분석은 빠지지 않고 계속 등장할 것이다.