일반적으로 원본 데이터 중 20%를 테스트 데이터셋에 할당한다. 그런 다음 나머지 80% 중 80%를 훈련 데이터셋에 사용하고, 나머지 20%를 검증 데이터셋으로 만든다. 그림 2-12는 이 과정을 그린 것이다.
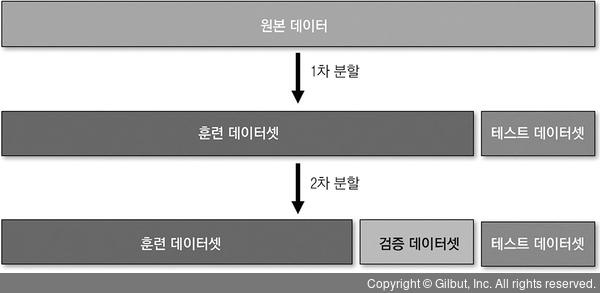
▲ 그림 2-12 데이터셋을 나누는 방식
여기서 중요한 점은 데이터를 무작위로 나눠야 한다는 것이다. 무작위가 아닌 방법으로 데이터를 나누면(예를 들어 순서대로 상위 80%를 훈련 데이터셋에 사용하면) 편향된 훈련 데이터셋과 테스트 데이터셋이 나올 수도 있다. 가령 시간 순서대로 저장된 원본 데이터의 상위 80%를 훈련 데이터셋으로 사용하면, 모델이 특정 날짜만 학습하게 되어 편향이 커지고 실세계에서도 잘 동작하지 못할 것이다.