카드 이용내역을 분석할 때도 같은 형식으로 했기 때문에 익숙할 테니 데이터의 차이만 짚고 넘어가겠습니다. data에는 총 32개 항목(열)이 있습니다. 데이터 항목 위에 열 인덱스를 넣어보면 다음과 같습니다. 실제로 data에는 헤더가 없지만, 각 열이 의미하는 바를 파악하기 쉽게 데이터 파일의 헤더를 보면서 진행하겠습니다.
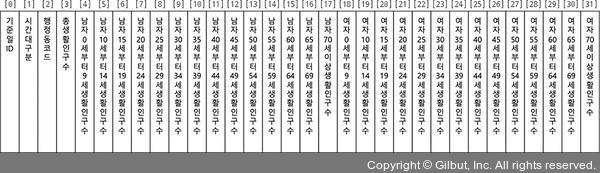
▲ 그림 11-17 인구 데이터의 헤더와 인덱스
과정 1에서 만든 population 리스트에 시간대별 평균인구를 담는 과정을 인구 데이터(data)의 첫 행부터 마지막 행까지 반복해야 하므로 과정 2에서는 이를 수행할 반복문을 작성합니다. 반복문에서 data의 한 행씩 row 변수에 담깁니다.
과정 2.1에서는 사용자가 입력한 행정동의 행정동코드(dong_code)와 data의 행정동코드가 같은지 한 행씩 확인합니다. data에서 행정동코드는 열 인덱스 [2]에 있으므로 row[2]가 됩니다. 따라서 dong_code와 row[2]가 같은지 if 조건문으로 확인합니다. 일치하는 행을 찾으면 과정 2.1.1로 가고 조건을 충족하지 않으면 다음 반복 회차로 넘어갑니다.