이 코드는 href 값인 “/sise/sise_market_sum.nhn?sosok=0&page=32”를 split 함수를 사용하여 =을 기준으로 구분하면 뒷부분에 저장된 페이지 번호를 숫자형으로 바꾸어 다시 total_page_num에 저장하겠다는 의미입니다.
total_page_num = int(total_page_num.get('href').split('=')[-1])
따라서 전체 실행 결과는 첫 번째 print 문을 사용하여 <a> 태그 정보가 나오고, 두 번째 print 문을 사용하여 32라는 전체 페이지 정보가 나오는 것입니다.
<a href="/sise/sise_market_sum.nhn?sosok=0&page=32">맨뒤
<img alt="" border="0" height="5" src="https://ssl.pstatic.net/static/n/cmn/bu_pgarRR.gif" width="8"/>
</a>
32
그럼 이제 우리가 작업해야 하는 반복 횟수(전체 페이지 수)를 알았으니 한 페이지씩 크롤링하는 방법을 알아보겠습니다. 먼저 페이지마다 얻을 수 있는 정보가 무엇이 있는지 알려면 제공되는 항목들을 담은 박스 정보를 크롤링해야 합니다. 이 박스의 HTML 태그 정보는 다음과 같습니다.
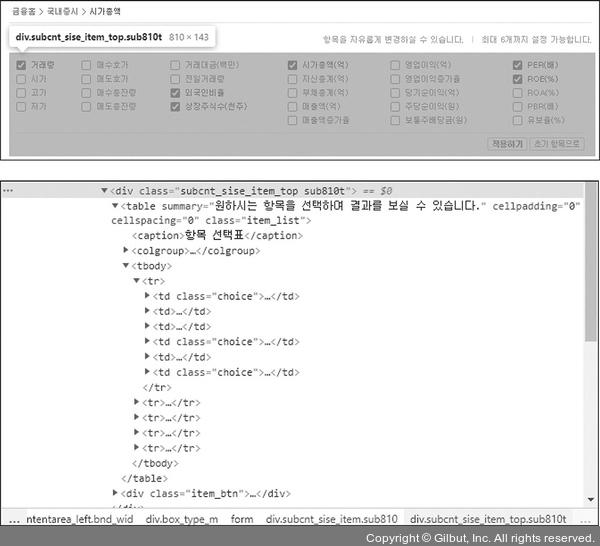
▲ 그림 5-30 항목 박스의 HTML 정보