읽기 부하가 큰 애플리케이션
일부 애플리케이션은 쓰기 작업보다 읽기 작업의 비율이 매우 높다. 비즈니스 인텔리전스와 다른 분석 애플리케이션들이 이런 범주에 속한다. 읽기 작업이 많은 애플리케이션은 결과를 걸러낼 수 있는 모든 필드를 인덱스로 가져가는 것이 좋다. 예를 들어 특정 판매 지역이나 특정 제품 카테고리에 속한 주문 항목을 자주 질의한다면 판매 지역과 제품 카테고리 필드를 인덱스로 만들어야 한다.
가끔은 어떤 필드가 결과를 걸러내는 데 사용되는지 알아내기가 쉽지 않은데 비즈니스 인텔리전스 애플리케이션의 경우가 그렇다. 한 분석가가 데이터 집합을 검사해 필드 여러 개를 필터로 선택했다고 해보자. 매번 새로운 질의를 수행할 때마다 이 분석가는 또 다른 필드를 필터로 사용하는 질의를 수행하게 될 것이다. 이 분석가가 질의를 자세히 파악하면 할수록 이런 반복적인 과정은 계속될 수 있다.
읽기 부하가 큰 애플리케이션은 많은 인덱스를 가질 수 있는데, 특히 질의 패턴을 알 수 없을 때 더욱 그렇다. 일반적으로 분석 애플리케이션에서는 결과를 걸러내는 데 사용할 수 있는 필드 대부분을 인덱스로 사용하고 있다(그림 8-9).
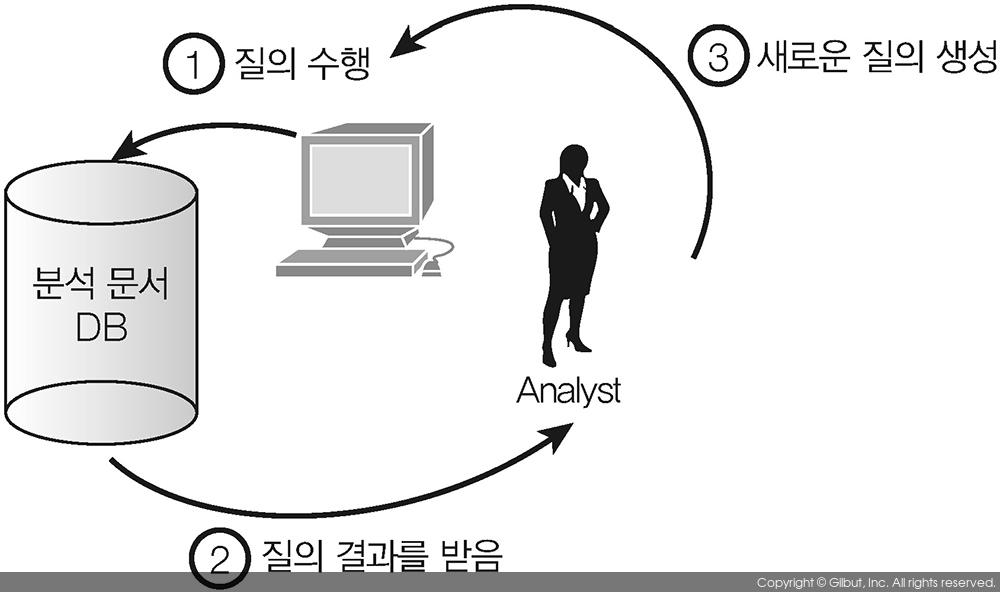
▲ 그림 8-9 분석 데이터베이스 질의는 반복 프로세스다. 사실상 모든 필드가 결과를 걸러내는 데 사용될 수 있다. 이럴 때 인덱스는 거의 모든 필드에 생성될 수 있다.