쓰기 부하가 큰 애플리케이션
쓰기 부하가 큰 애플리케이션은 읽기 작업보다 쓰기 작업의 비중이 높은 것을 말한다. 이전에 예로 들었던 트럭 운행 데이터를 받는 문서 데이터베이스는 쓰기 작업이 많은 데이터베이스일 것이다. 인덱스를 생성하고 갱신하는 별도의 데이터 구조이므로 인덱스를 사용할 때 CPU, 스토리지, 메모리 자원을 소모하고, 이로 인해 데이터베이스에 문서를 삽입하거나 갱신하는 데 걸리는 시간도 증가할 것이다.
데이터 모델러들은 쓰기 작업이 많은 애플리케이션에서는 될 수 있으면 인덱스의 수를 최소화하려는 경향이 있다. 관련 문서의 식별자를 저장해 놓은 필드처럼 필수적인 인덱스는 만들어야 한다. 다른 것에 중점을 두고 설계할 경우 쓰기 작업이 많은 애플리케이션에서 인덱스의 수를 결정하는 것은 여러 이해관계 속에서 균형을 잡는 문제라 볼 수 있다.
보통 인덱스의 수가 적으면 갱신속도는 빠르지만 읽기 속도는 느려질 수 있다. 읽기 작업을 수행하는 사용자들이 결과를 받기까지 어느 정도의 지연은 기다릴 수 있다면 인덱스를 최소화하는 것이 좋다. 하지만 쓰기 부하가 큰 데이터베이스인데 짧은 대기 시간이 중요한 요소라면 시간이 많이 소요되는 질의가 반환하는 결과를 집계해 놓은 두 번째 데이터베이스를 구축하는 것도 고려해 볼 수 있다. 이런 형태가 비즈니스 인텔리전스에서 사용되는 기본 모델이다.
트랜잭션 처리 시스템은 빠른 쓰기 작업과 목표로 설정한 읽기 속도를 보장하도록 설계되었다. 추출, 가공, 적재(ETL) 프로세스를 사용하는 데이터베이스에 있는 데이터는 복사되어 데이터 마트나 데이터 웨어하우스에 적재된다. 데이터 마트나 데이터 웨어하우스에는 보통 질의 응답시간을 향상시키기 위해 많은 인덱스가 있다(그림 8-10).
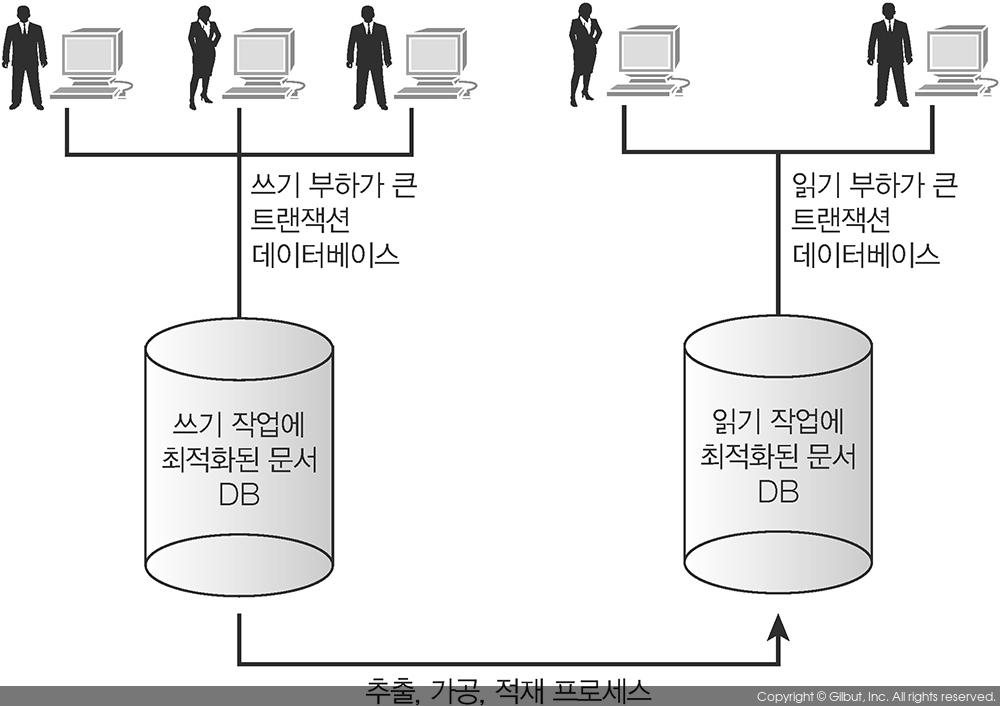
▲ 그림 8-10 읽기 작업도 많고 쓰기 작업도 많은 애플리케이션을 지원해야 한다면 데이터베이스를 두 개 운영하는 것이 제일 나은 선택이 될 수 있다
Tip 몇 가지 실험을 통해 애플리케이션에 적당한 인덱스 수를 찾아낼 수 있다. 일단 가장 중요하고 가장 빈번히 실행되는 질의의 수행시간을 줄이기 위해 인덱스를 만들어라. 애플리케이션에 읽기 작업뿐만 아니라 쓰기 작업도 많다면 두 가지 유형별로 최적화된 두 개의 데이터베이스를 운용하는 것을 검토해 보자.