5.5 카탈리스트 최적화 엔진
DataFrame과 Dataset 두뇌라고 할 수 있는 카탈리스트 최적화 엔진(Catalyst optimizer)은 DataFrame DSL과 SQL 표현식을 하위 레벨의 RDD 연산으로 변환한다. 사용자는 카탈리스트를 손쉽게 확장해 다양한 최적화를 추가로 적용할 수 있다.
그림 5-5는 카탈리스트 엔진을 최적화하는 과정 전반을 도식화한 것이다. 카탈리스트는 먼저 DSL 및 SQL 표현식에서 파싱 완료된 논리 실행 계획(parsed logical plan)을 생성한다. 그런 다음 쿼리가 참조하는 테이블 이름, 칼럼 이름, 클래스 고유 이름(qualified name) 등(카탈리스트에서는 이들을 릴레이션(relation)이라고 한다) 존재 여부를 검사하고, 분석 완료된 논리 실행 계획(analyzed logical plan)을 생성한다. 다음 단계에서 카탈리스트는 하위 레벨 연산을 재배치하거나 결합하는 등 여러 방법으로 실행 계획의 최적화를 시도한다. 예를 들어 카탈리스트는 조인할 데이터양을 줄이려고 조인 연산 다음에 사용한 필터링 연산을 조인 앞으로 옮기기도 한다. 최적화 단계를 완료하면 최적화된 논리 실행 계획(optimized logical plan)을 생성한다. 마지막으로 카탈리스트는 최적화된 논리 실행 계획에서 실제 물리 실행 계획(physical plan)을 작성한다. 향후 공개할 스파크 버전에서는 여러 물리 실행 계획을 생성하고 비용 모델(cost model)을 기반으로 최적의 계획을 선택하는 로직을 도입할 예정이다.23
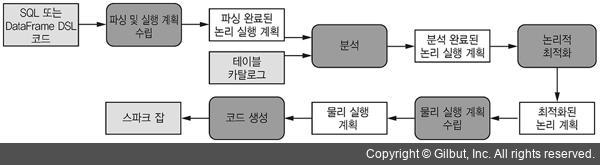
▲ 그림 5-5 카탈리스트 엔진이 SQL 및 DSL 표현식을 RDD 연산으로 변환하는 과정(파싱 및 분석, 논리적 최적화, 물리 실행 계획 수립, 코드 생성 단계로 진행한다.)
23 역주 이 기능은 비용 기반 최적화(Cost Based Optimizer, CBO)란 이름으로 스파크 버전 2.2(2017년 7월 11일 공개)에 포함되었다. 자세한 내용은 데이터브릭스의 블로그(https://goo.gl/7KYNNR)를 참고하자.