앞의 예에서 머신 러닝은 복잡한 문제 해결을 위한 규칙 탐색을 자동화하는 과정으로 볼 수 있습니다. 이런 자동화는 사람이 직관적으로 규칙을 알고 데이터에 쉽게 레이블을 부여할 수 있는 얼굴 감지 같은 문제에 도움이 됩니다. 어떤 문제에서는 직관적으로 규칙을 알기 어렵습니다. 예를 들어 웹 페이지 내용과 광고 콘텐츠, 시간과 장소 같은 다른 정보가 주어졌을 때 사용자가 웹 페이지의 광고를 클릭할지 예측하는 문제를 생각해 보죠. 누구도 일반적으로 이런 문제에 대해 정확히 예측하는 방법을 알지 못합니다. 만약 안다고 해도 시간과 표시되는 페이지 콘텐츠, 광고의 변화에 따라 패턴이 바뀔 것입니다. 하지만 광고 전송 기록에서 레이블된 훈련 데이터를 얻을 수 있습니다. 데이터와 레이블이 있다면 이와 같은 문제에는 머신 러닝이 잘 맞습니다.
그림 1-3에 머신 러닝의 단계가 자세히 나타나 있습니다. 두 개의 중요한 단계가 있습니다. 첫 번째는 훈련 단계입니다. 이 단계는 데이터와 정답을 받습니다. 이 둘을 합쳐 훈련 데이터(training data)라고 부릅니다. 입력 데이터와 정답의 각 쌍을 샘플(example)12이라고 부릅니다. 샘플을 사용해 훈련 과정에서 자동으로 규칙(rule)을 찾습니다. 자동으로 규칙을 찾지만 완전히 밑바닥부터 찾는 것은 아닙니다. 다른 말로 하면, 머신 러닝 알고리즘은 규칙 탐색에 창의적이지 않습니다. 엔지니어는 훈련 초기에 규칙에 대한 청사진을 제공합니다. 이 청사진은 모델(model)에 캡슐화되어 있으며 기계가 학습할 수 있는 규칙에 대한 가설 공간(hypothesis space)을 형성합니다. 가설 공간이 없으면 탐색할 규칙의 공간이 완전히 제약이 없고 무한하며, 제한된 시간 안에 좋은 규칙을 찾는 데 바람직하지 않습니다. 가능한 모델 종류와 현재 문제에 맞는 가장 좋은 모델을 선택하는 방법을 자세히 설명하겠습니다. 지금은 딥러닝 관점으로 보았을 때 신경망을 구성하는 층의 개수, 층의 종류, 층의 연결 방식에 따라 모델이 다양하다고 이해하는 것으로 충분합니다.
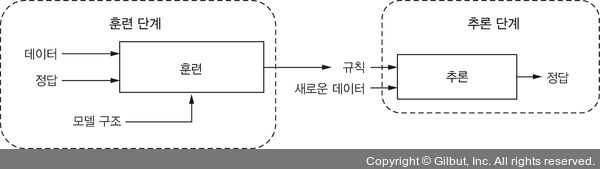
▲ 그림 1-3 머신 러닝 패러다임을 그림 1-2보다 자세하게 나타낸 그림이다. 머신 러닝의 워크플로는 훈련과 추론 두 단계로 구성되는데, 훈련은 머신 러닝이 데이터를 정답으로 변환하는 규칙을 자동으로 찾는 단계다. 훈련된 ‘모델’에 캡슐화된 학습 규칙은 훈련 단계의 결과물이고 추론 단계의 기초를 형성한다. 추론은 모델을 사용해 새로운 데이터에 대한 정답을 얻는 과정이다.