INFO BOX 1.2 GPU와 WebGL을 사용한 가속 컴퓨팅
머신 러닝 모델을 훈련하고 이를 사용해 추론을 수행하려면 아주 많은 개수의 수학 연산이 필요합니다. 예를 들어 많이 사용되는 ‘밀집’ 신경망 층은 큰 행렬과 벡터를 곱하고 그 결과에 또 다른 벡터를 더합니다. 일반적으로 이런 종류의 연산에는 수천 또는 수백만 개의 부동소수점 연산이 필요합니다. 이런 연산에서 중요한 사실은 많은 경우에 병렬화가 가능하다는 것입니다. 예를 들어, 두 벡터의 덧셈은 두 개의 개별 숫자에 대한 덧셈처럼 많은 개수의 작은 연산으로 나눌 수 있습니다. 이런 작은 연산 사이에는 의존성이 없습니다. 예를 들어, 두 벡터의 인덱스 1 위치에 있는 두 원소의 합을 계산하기 위해 인덱스 0 위치에 있는 원소 간의 합을 알 필요가 없습니다. 결과적으로 벡터의 길이에 상관없이 이런 작은 연산들은 한 번에 하나씩이 아니라 동시에 수행될 수 있습니다. CPU의 벡터 덧셈 구현 같은 직렬 계산을 SISD(Single Instruction Single Data)라고 합니다. GPU의 병렬 계산은 SIMD(Single Instruction Multiple Data)라고 합니다. 일반적으로 개별 덧셈을 계산하는 데는 CPU가 GPU보다 빠릅니다. 하지만 대규모 데이터에 대한 전체 비용은 GPU의 SIMD가 CPU의 SISD를 능가합니다. 심층 신경망은 수백만 개의 파라미터를 가질 수 있습니다. 주어진 입력에 대해 (적어도) 수십억 개의 원소별 수학 연산을 실행할 필요가 있습니다. GPU가 제공하는 대규모 병렬 계산은 이런 규모에서 진짜 빛을 발합니다.
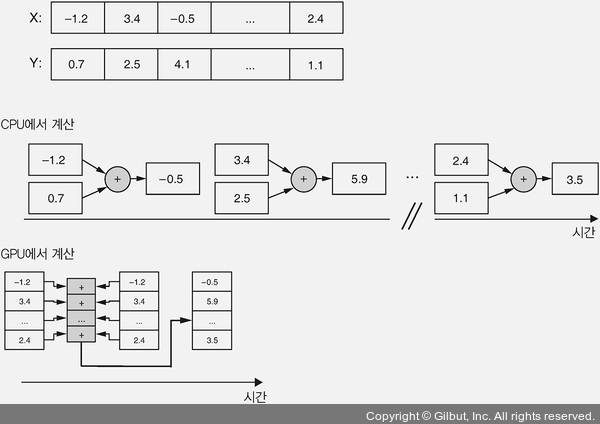
▲ 그림 1-6 WebGL 가속이 GPU 병렬 계산 능력을 활용하여 CPU보다 빠른 벡터 연산을 수행하는 방법
엄밀히 말하면 최신 CPU는 어느 정도 수준의 SIMD 연산도 수행할 수 있습니다. 하지만 GPU가 (수천 또는 수백 배나) 훨씬 많은 개수의 프로세싱 유닛을 가지고 있고 입력 데이터를 잘게 쪼개어 동시에 명령을 실행할 수 있습니다. 벡터 덧셈은 비교적 간단한 SIMD 작업입니다. 계산 각 단계에서 하나의 인덱스만 바라보며 다른 인덱스에서의 결과는 서로 독립적입니다. 머신 러닝에는 더 복잡한 SIMD 작업이 있습니다. 예를 들어 행렬 곱셈에서 계산 단계마다 여러 인덱스의 데이터를 사용하고 인덱스 사이에 의존성이 있습니다. 하지만 병렬화를 통한 가속의 기본 아이디어는 동일합니다.
흥미롭게도 GPU는 원래 신경망을 가속하기 위해 고안되지 않았습니다. 그래픽 프로세싱 유닛(graphics processing unit)이란 이름에서 알 수 있듯이, GPU의 주요 목적은 2D와 3D 그래픽을 처리하는 것입니다. 3D 게임 같은 많은 그래픽 애플리케이션에서 부드러운 게임 진행을 위해 충분히 빠른 프레임 속도(frame rate)로 화면의 이미지를 업데이트할 수 있도록 가능한 한 빠르게 처리하는 것이 중요합니다. 이것이 SIMD 병렬화를 사용하는 GPU를 만든 원래의 동기입니다. 하지만 놀랍게도 이런 종류의 병렬 컴퓨팅 GPU는 머신 러닝의 요구에도 잘 들어맞습니다.
GPU 가속을 위해 TensorFlow.js가 사용하는 WebGL 라이브러리는 원래 웹 브라우저에서 3D 객체의 텍스처(표면 패턴) 렌더링 같은 작업을 위해 고안되었습니다. 그런데 텍스처는 숫자의 배열에 불과합니다! 따라서 이 숫자를 신경망의 가중치나 활성화 값으로 생각하고 WebGL의 SIMD 텍스처 연산을 이용해 신경망을 실행할 수 있습니다. 이것이 TensorFlow.js가 브라우저에서 신경망을 가속하는 방법입니다.