샘플에 있는 모든 양성 샘플 중에서 모델이 찾아낸 양성 샘플은 얼마나 될까요? 누락될 가능성을 낮추기 위해 잘못된 경보25의 비율을 의식적으로 올리는 결정을 합니다. 이 지표를 속이려면 단순히 모든 샘플을 양성으로 예측하면 됩니다. 거짓 양성이 이 식에 포함되지 않기 때문에 정밀도가 감소되지만 100% 재현율을 얻을 수 있습니다.
여기서 볼 수 있듯이 정확도, 재현율, 정밀도에서 높은 점수를 받는 시스템을 만드는 것은 매우 쉽습니다. 실전 이진 분류 문제에서 정밀도와 재현율을 동시에 만족시키기가 어려운 경우가 많습니다. (만약 이렇게 하기 쉽다면 간단한 문제이고, 아마도 처음부터 머신 러닝을 사용할 필요가 없었을 것입니다.) 정밀도와 재현율은 정답이 무엇인지 근본적으로 불확실한 까다로운 영역에서 모델을 튜닝하는 것입니다. X%의 재현율에서의 정밀도와 같이 미묘하고 복합적인 지표를 보게 될 것입니다. 여기서 X는 90과 같은 값입니다. 적어도 양성 샘플의 X%를 찾도록 튜닝한다면 정밀도는 얼마가 될까요? 예를 들어, 그림 3-5에서 모델 확률 출력의 임계값이 0.5일 때 400번의 에포크 후에 피싱 감지 모델이 96.8%의 정밀도와 92.9%의 재현율을 달성합니다.
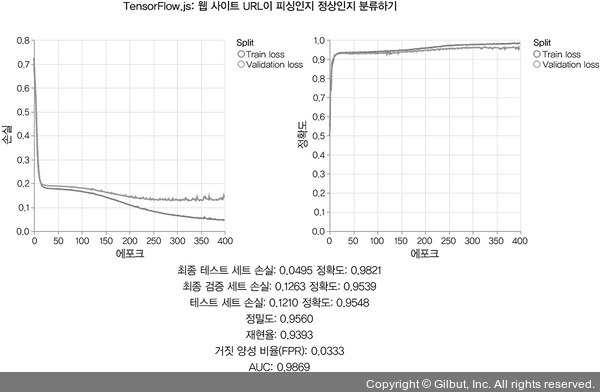
▲ 그림 3-5 피싱 웹 페이지 감지 모델의 훈련 결과. 아래에 나타나 있는 다양한 측정값(정밀도, 재현율, FPR)을 주의 깊게 보자. AUC는 3.2.3절에서 설명한다.