4.1 벡터에서 텐서로 이미지 표현하기
앞의 두 장에서는 수치 입력을 다루는 머신 러닝 작업을 살펴보았습니다. 예를 들어 2장의 다운로드 시간 예측 문제는 하나의 숫자(파일 크기)를 입력으로 사용합니다. 보스턴 주택 문제의 입력은 12개의 숫자 배열(방 개수, 범죄율 등)입니다. 이런 문제들의 공통점은 입력 샘플을 (중첩되지 않은) 하나의 1차원 숫자 배열로 표현할 수 있다는 것입니다. TensorFlow.js에서는 1D 텐서에 해당합니다. 하지만 이미지는 딥러닝에서 다르게 표현됩니다.
이미지는 3D 텐서를 사용해 나타냅니다. 이 텐서의 처음 두 개 차원은 높이와 너비 차원으로, 익숙합니다. 세 번째 차원은 컬러 채널입니다. 예를 들어 컬러는 종종 RGB 값으로 인코딩됩니다. 이 경우에 세 개의 컬러 각각이 하나의 채널이 됩니다. 따라서 세 번째 차원의 크기는 3이 됩니다. 224 × 224 픽셀 크기의 RGB 인코딩된 컬러 이미지가 있다면 [224, 224, 3] 크기의 3D 텐서로 나타낼 수 있습니다. 일부 컴퓨터 비전 문제의 이미지는 컬러가 없습니다(즉, 흑백입니다). 이런 경우에는 하나의 채널만 있으므로 3D 텐서로 나타내면 [height, width, 1] 크기3가 됩니다(그림 4-1 참조).4
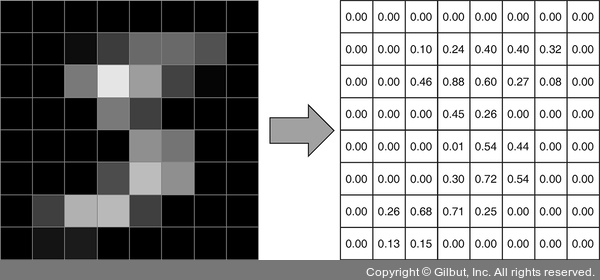
▲ 그림 4-1 딥러닝에서 MNIST 이미지를 텐서로 표현하기. 그림으로 나타내기 위해 MNIST 이미지를 28 × 28에서 8 × 8로 줄였다. 이 이미지는 흑백 이미지5라서 높이, 너비, 컬러 채널로 이루어진 [8, 8, 1] 크기다. 마지막 차원에 있는 하나의 컬러 채널은 이 그림에 나타나 있지 않다.6