이 모델의 summary() 메서드 출력은 다음에 나타나 있습니다.
_________________________________________________________________ Layer (type) Output shape Param # ================================================================= flatten_Flatten1 (Flatten) [null,784] 0 _________________________________________________________________ dense_Dense1 (Dense) [null,42] 32970 _________________________________________________________________ dense_Dense2 (Dense) [null,10] 430 ================================================================= Total params: 33400 Trainable params: 33400 Non-trainable params: 0 _________________________________________________________________
같은 훈련 설정을 사용해서 합성곱 층을 사용하지 않은 모델의 훈련 결과를 그림 4-8과 같이 얻었습니다. 열 번의 훈련 에포크 후에 얻은 최종 평가 정확도는 97.0%입니다. 2% 포인트 차이가 작게 보일 수 있지만, 에러율의 관점에서 보면 합성곱 층을 사용하지 않은 모델이 합성곱 신경망보다 세 배나 나쁩니다. 간단한 실습으로 createDenseModel() 함수에 있는 은닉층(첫 번째 밀집 층)의 units 매개변수를 증가시켜 합성곱 층을 사용하지 않은 모델의 파라미터 개수를 늘려 보세요. 파라미터 개수를 증가시켜도 밀집 층만 사용한 모델이 합성곱 신경망의 정확도를 달성하기는 어렵습니다. 이를 통해 합성곱 신경망의 강력함을 알 수 있습니다. 파라미터 공유와 시각적 특성의 국소성을 활용하여 합성곱 신경망은 합성곱 층을 사용하지 않은 신경망보다 적거나 비슷한 파라미터 개수로 컴퓨터 비전에서 뛰어난 정확도를 달성합니다.
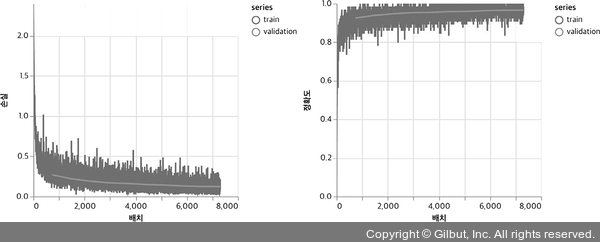
▲ 그림 4-9 그림 4-8과 비슷하지만, 코드 4-3에 있는 createDenseModel() 함수로 만든 합성곱 층을 사용하지 않은 MNIST 모델