plyr의 병렬화
plyr의 함수들 중 {adl}{adl_}ply 형태 함수들의 도움말을 살펴보면 .parallel 옵션이 있다. 이 옵션 값이 TRUE로 설정되면 registerDoParallel( )을 사용해 설정한 만큼의 프로세스가 동시에 실행되어 데이터를 병렬적으로 처리한다. 그리고 그 결과들은 자동으로 하나의 결과로 병합되어 사용자에게 반환된다. 그러나 .parallel의 기본값은 FALSE므로 이 옵션을 명시적으로 설정하지 않으면 registerDoParallel( )을 호출했다 하더라도 병렬화가 사용되지 않는다.
.parallel=TRUE를 지정하는 예를 살펴보자. 다음 코드는 value에는 값, group에는 그룹을 나타내는 알파벳이 담긴 데이터 프레임을 만든 다음 각 그룹별 value의 평균을 구한다.
> library(doParallel) > library(plyr) > registerDoParallel(cores=4) > big_data <- data.frame( + value=runif(NROW(LETTERS) * 2000000), + group=rep(LETTERS, 2000000)) > dlply(big_data, .(group), function(x) { + mean(x$value) + }, + .parallel=TRUE)
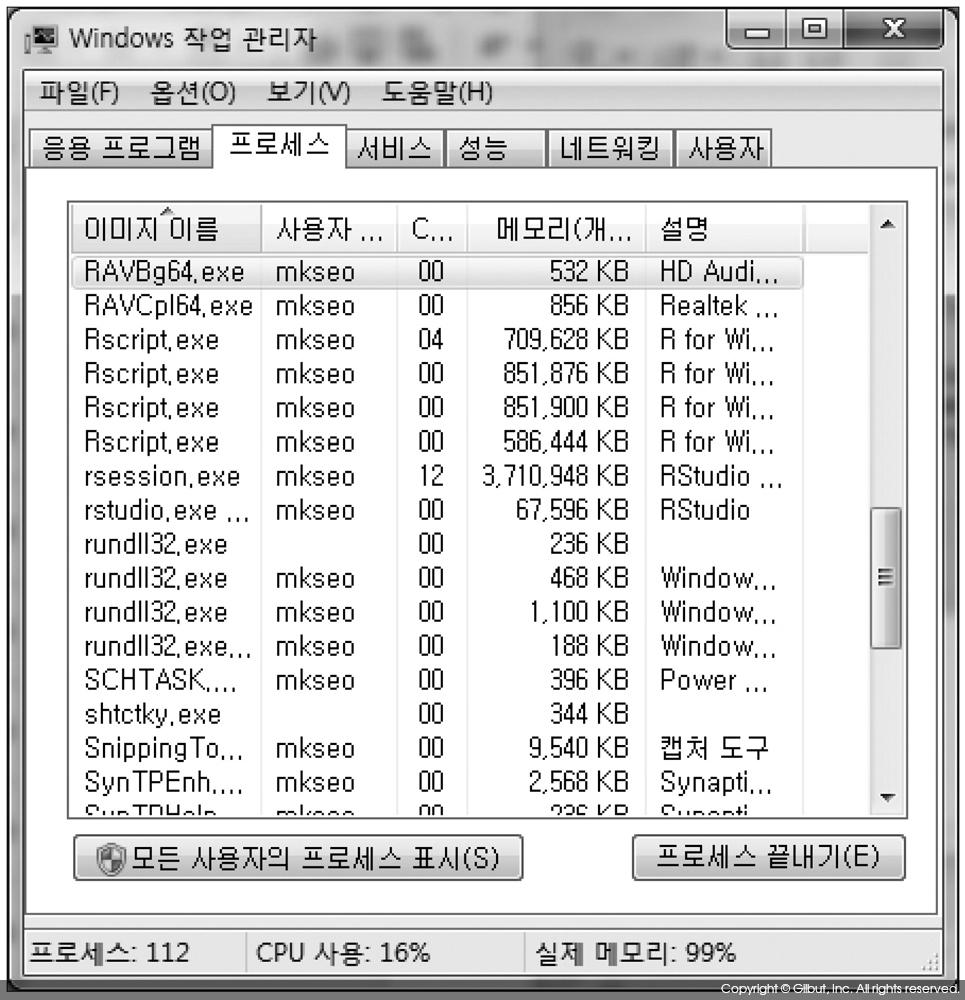
위 코드를 실행한 다음 프로세스를 관찰해보면 그림 5-2에서 볼 수 있듯이 다수의 R 프로세스가 실행되어 있고 이들이 대량의 메모리를 소모함을 알 수 있다. 그림 5-1과 달리 그림 5-2의 Rscript.exe들이 수백 MB의 메모리를 사용하고 있음을 주목하기 바란다.
이처럼 대량의 데이터를 병렬로 처리할 때는 프로세스의 실행을 관찰하면서 시스템 전체의 가용 메모리가 얼마나 남아 있는지를 확인해야 한다. 메모리가 부족하면 부족한 메모리를 보충하기 위해 디스크를 메모리처럼 사용하게 되고, 디스크 입출력 작업 때문에 데이터 처리의 속도가 느려지는 스래싱thrashing 현상이 발생할 수 있기 때문이다.