데이터 변환
데이터 정규화(Feature Scaling)
데이터 정규화는 변숫값의 분포를 표준화하는 것을 의미한다. 표준화는 변수에서 데이터의 평균을 빼거나 변수를 전체 데이터의 표준 편차로 나누는 작업을 포함한다. 이렇게 하면 변숫값의 평균이 0이 되고 값의 퍼짐 정도(분포) 또한 일정해진다.
데이터 정규화는 k 최근 이웃 분류 알고리즘kNN, k-Nearest Neighbor, 서포트 벡터 머신SVM, Support Vector Machine, 신경망Neural Network 등 많은 분류 알고리즘에서 유용하게 사용된다.[4] R에서 데이터를 정규화하는 함수는 scale( )이다.
|
scale : 행렬 유형의 데이터를 정규화한다. |
scale( x, # 숫자 벡터 유형의 객체 center=TRUE, # TRUE면 모든 데이터에서 전체 데이터의 평균을 뺀다. # scale이 TRUE일 때 center도 TRUE면 모든 데이터를 전체 데이터의 표준 편차로 나눈다. # scale이 TRUE지만 center는 FALSE면 모든 데이터를 전체 데이터의 제곱 평균 제곱근으로 나눈다. # scale이 FALSE면 데이터를 어떤 값으로도 나누지 않는다. scale=TRUE ) 반환 값은 정규화된 데이터 행렬이다. |
제곱 평균 제곱근은 전체 데이터의 제곱의 평균에 루트를 씌운 것을 뜻한다. 데이터가 x1, x2, x3, ..., xn으로 주어졌을 때 RMS는 다음과 같다.
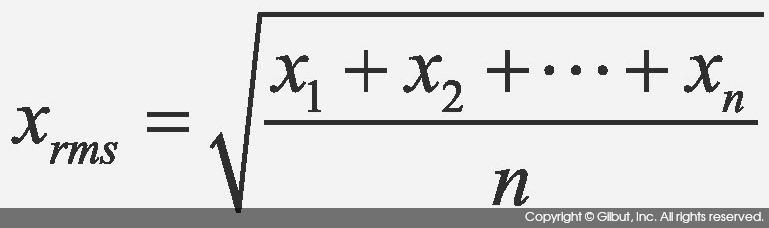
다음은 아이리스 데이터의 값을 정규화한 예다. scale( )이 행렬을 반환하므로 이를 다시 데이터 프레임으로 변환하기 위해 as.data.frame( )을 사용했으며, Species는 정규화에서 제외했다가 후에 cbind( )로 합쳤다.
> cbind(as.data.frame(scale(iris[1:4])), iris$Species)
Sepal.Length Sepal.Width Petal.Length Petal.Width iris$Species
1 -0.89767388 1.01560199 -1.33575163 -1.3110521482 setosa
2 -1.13920048 -0.13153881 -1.33575163 -1.3110521482 setosa
3 -1.38072709 0.32731751 -1.39239929 -1.3110521482 setosa
4 -1.50149039 0.09788935 -1.27910398 -1.3110521482 setosa
5 -1.01843718 1.24503015 -1.33575163 -1.3110521482 setosa
6 -0.53538397 1.93331463 -1.16580868 -1.0486667950 setosa
...