모델 진단 그래프
단순히 plot(m) 명령을 내리는 것만으로 선형 회귀 모델을 평가하는 데 필요한 다양한 차트를 볼 수 있다. 이 함수는 일반 함수므로, 인자로 선형 모델이 주어지면 plot.lm( )을 호출한다.
|
plot.lm : lm 객체에 대한 진단 그래프를 그린다. |
plot.lm( x, # 선형 모델 which=c(1:3, 5) # 그릴 그래프의 종류. 1~6의 총 6가지 그래프가 있다. ) |
다음은 차량의 주행 속도와 제동 거리를 모델링한 선형 회귀 모델에 plot()을 실행한 결과다. 코드 실행 결과는 그림 8-2에 보였다.
> plot(m)
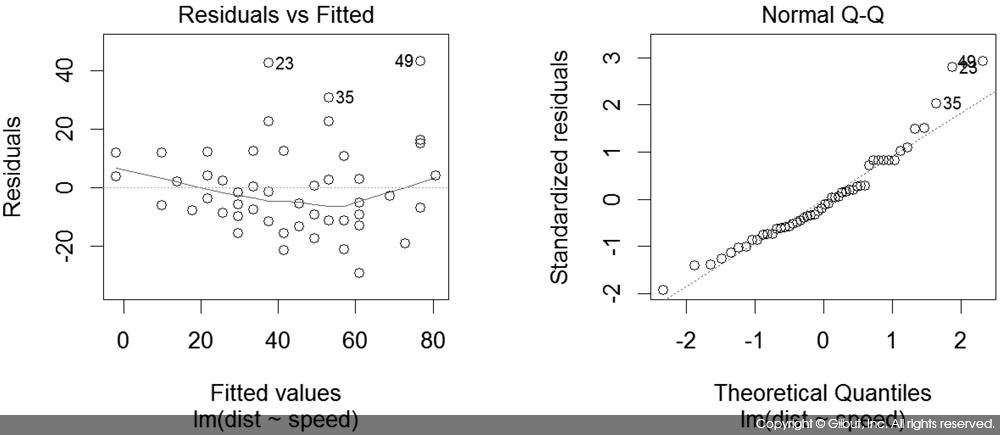
첫 번째 차트인 Residuals vs Fitted는 X 축에 선형 회귀로 예측된 Y 값, Y 축에는 잔차를 보여준다. 선형 회귀에서 오차는 평균이 0이고 분산이 일정한 정규 분포를 가정하였으므로, 예측된 Y 값과 무관하게 잔차의 평균은 0이고 분산은 일정해야 한다. 따라서 이 그래프에서는 기울기 0인 직선이 관측되는 것이 이상적이다.
두 번째 차트인 Normal Q-Q는 잔차가 정규 분포를 따르는지 확인하기 위한 Q-Q도다.
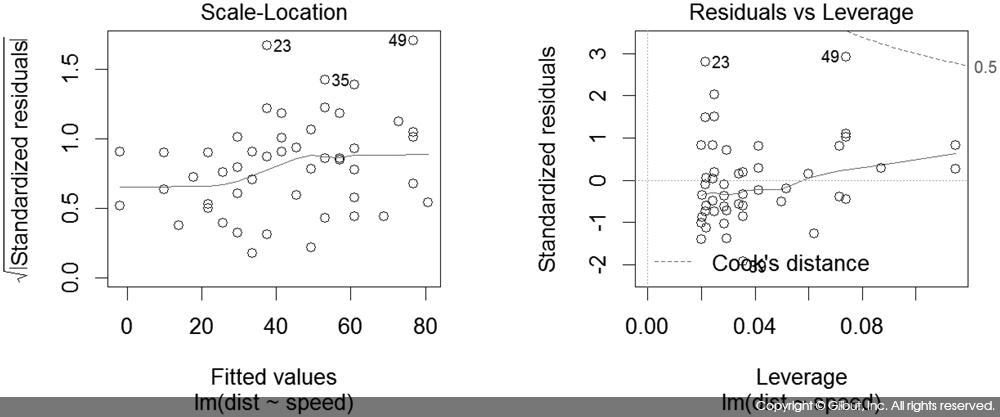
세 번째 차트인 Scale-Location은 X 축에 선형 회귀로 예측된 Y 값, Y 축에 표준화 잔차Standardized Residual3 를 보여준다. 이 경우도 기울기가 0인 직선이 이상적이다. 만약 특정 위치에서 0에서 멀리 떨어진 값이 관찰된다면 해당 점에 대해서 표준화 잔차가 크다, 즉, 회귀 직선이 해당 Y를 잘 적합하지 못한다는 의미다. 이런 점들은 이상치outlier일 가능성이 있다.
네 번째 차트인 Residuals vs Leverage는 X 축에 레버리지Leverage, Y 축에 표준화 잔차를 보여준다. 레버리지는 설명 변수가 얼마나 극단에 치우쳐 있는지를 뜻한다. 예를 들어, 다른 데이터의 X 값은 모두 1 ~ 10 사이의 값인데 특정 데이터만 99999 값이라면 해당 데이터의 레버리지는 큰 값이 된다. 이런 데이터는 입력이 잘못되었거나, 해당 범위의 설명 변숫값을 가지는 데이터를 보충해야 하는 작업 등이 필요하므로 유심히 살펴봐야 한다.
네 번째 차트의 우측 상단과 우측 하단에는 선으로 쿡의 거리Cook’s Distance가 표시되어 있다. 쿡의 거리는 회귀 직선의 모양(기울기나 절편 등)에 크게 영향을 끼치는 점들을 찾는 방법이다. 쿡의 거리는 레버리지와 잔차에 비례하므로 두 값이 큰 우측 상단과 우측 하단에 쿡의 거리가 큰 값들이 위치하게 된다. 이 차트에 더 관심이 있는 독자는 인터넷에 공개된 책자인 <Advanced Statistical Modelling>[9]을 참고하거나, 그림과 예제로 매우 잘 설명한 같은 강의의 PPT 슬라이드[10]에서 이상치 진단에 대한 내용을 참고하기 바란다.
plot.lm( )이 그리는 차트는 앞서 보인 4가지 차트 외에도 2가지가 더 있다. 이들 차트를 보려면 which에 차트 번호 c(4, 6)을 다음과 같이 지정한다(which의 기본값은 c(1:3, 5)이므로 plot.lm( )은 1, 2, 3, 5번째 차트를 기본으로 보여준다).
> plot(m, which=c(4, 6))
다음은 앞의 코드를 실행한 결과다.
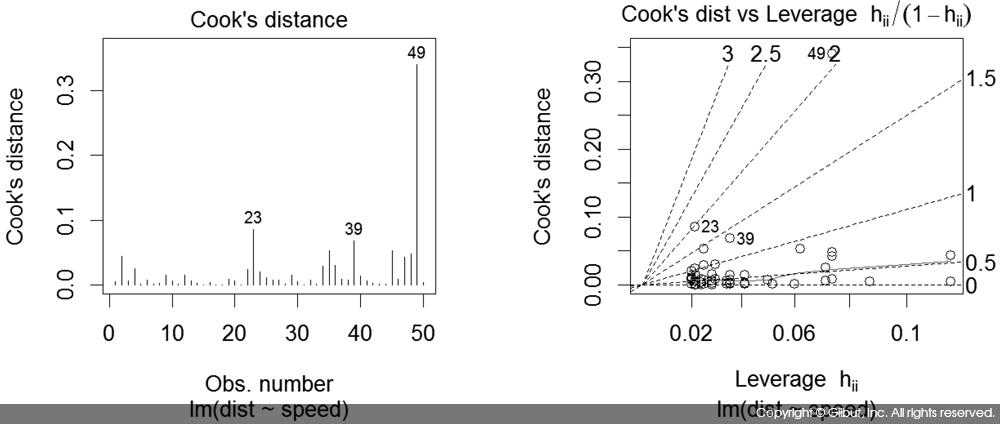
첫 번째 그래프는 관측값의 순서별 쿡의 거리, 두 번째 차트는 레버리지와 쿡의 거리를 보여준다.
3 표준화 잔차는 ‘잔차 / 잔차의 표준 편차’로 계산한다. 말 그대로 잔차의 분산을 없애 표준화한 잔차다.