04 | 문자열(text)
text( )는 그래프에 문자열을 그리는 데 사용한다.
|
text : 그래프에 문자열을 추가한다. |
text( x, # X 좌표 y=NULL, # Y 좌표 labels=seq_along(x), # 표시할 문자열 # adj와 pos는 텍스트의 위치를 지정하는 옵션으로, # 값이 지정하지 않을 경우 주어진 좌표에 정확히 문자열이 출력된다. # adj는 텍스트의 위치를 지정하는 옵션으로, 값 0 또는 1인 길이 2인 벡터를 지정할 수 있다. # (0, 0)은 좌표의 우측 상단, (0, 1)은 우측 하단, (1, 0)은 좌측 상단, # (1, 1)은 좌측 하단에 문자열을 표시한다. adj=NULL, # pos 역시 문자열의 위치를 지정하는 옵션이다. pos와 adj를 동시에 지정하면 pos가 우선한다. # pos 값 1은 좌표의 하단, 2는 좌측, 3은 상단, 4는 우측에 문자열을 표시한다. pos=NULL, ... ) |
adj 옵션의 의미를 이해하기 위해 (4, 4), (5, 5), (6, 6) 좌표에 점을 그리고 (5, 5)를 기준으로 서로 다른 adj에 따라 문자열을 표시해보자.
> plot(4:6, 4:6) > text(5, 5, "X") > text(5, 5, "00", adj=c(0, 0)) > text(5, 5, "01", adj=c(0, 1)) > text(5, 5, "10", adj=c(1, 0)) > text(5, 5, "11", adj=c(1, 1))
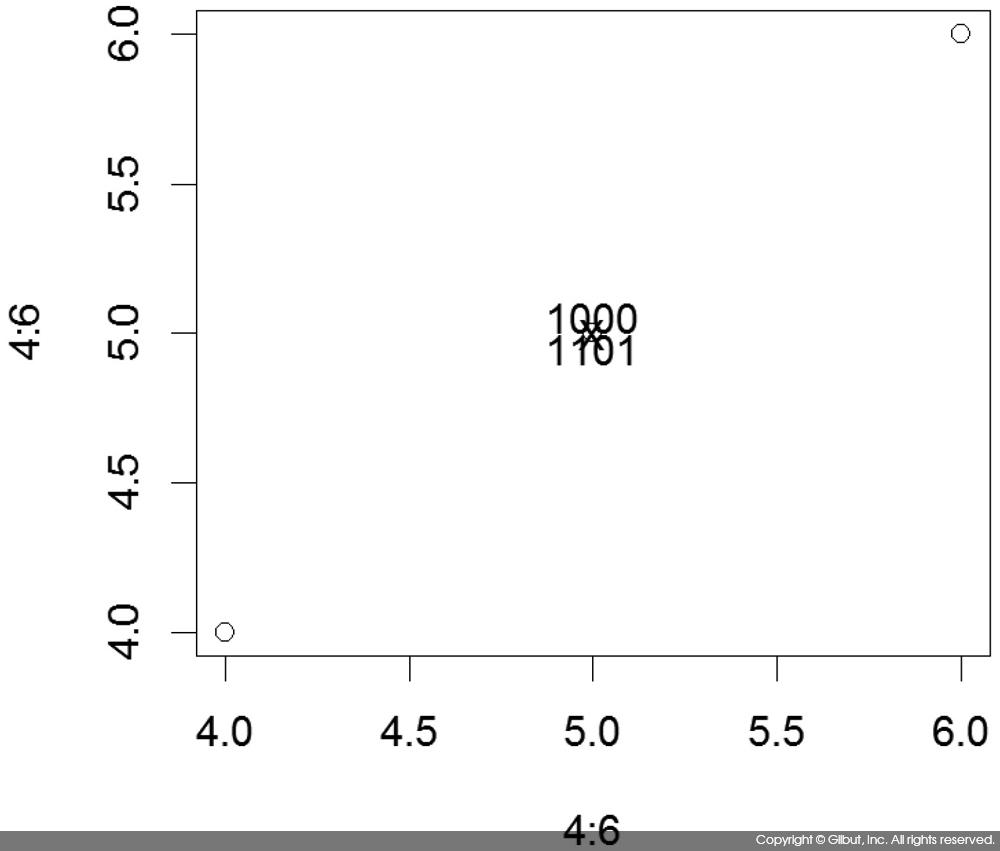
실행 결과 (5, 5) 위치에 문자열을 출력하더라도 adj에 따라 문자열 위치가 조정되는 것을 볼 수 있다.
text( )에서 labels 값이 주어지지 않을 경우 기본값은 seq_along(x)다. seq_along(x)는 1, 2, 3, …, NROW(x)까지의 정수를 반환하는 함수다. 따라서 labels를 지정하지 않으면 (x, y) 좌표들에 데이터 순서에 따라 번호를 붙이게 된다. 다음은 cars 데이터의 각 점에 데이터 번호를 표시하는 예다.
> plot(cars, cex=.5) > text(cars$speed, cars$dist, pos=4)
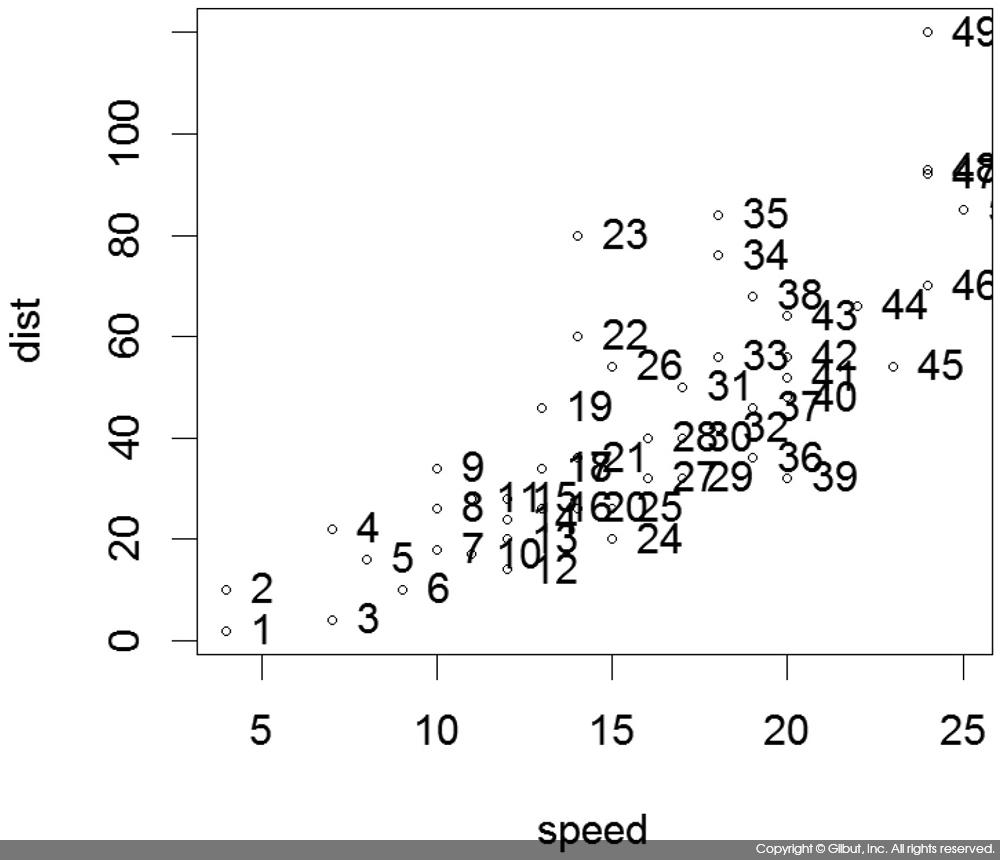
이처럼 text( )를 사용하면 점들에 번호를 붙여 각 점이 어느 데이터에 해당하는지 쉽게 알 수 있다. 그러나 데이터가 몰려 있는 점에서는 숫자가 겹쳐서 표시되므로, 각 점이 어느 데이터에 해당하는지 구분이 어렵다. 또, 항상 모든 점에 레이블이 필요한 것은 아니다. 이런 경우에는 다음 절에서 설명할 identify( )를 사용한다.