표본 평균, 표본 분산, 표본 표준 편차
표본 평균, 표본 분산, 표본 표준 편차는 표본 X1, X2, …, Xn의 n개 표본이 있을 때 다음과 같이 계산한다.
|
통계량 |
수식 |
|
표본 평균 |
|
|
표본 분산 |
|
|
표본 표준 편차 |
|
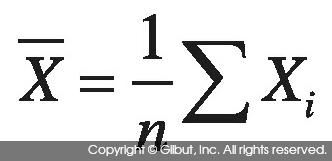
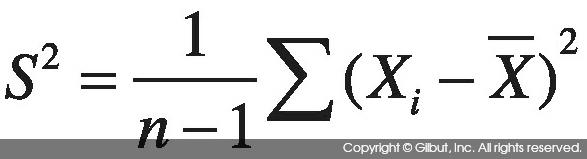
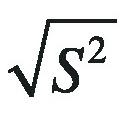
분산의 계산에서 분모에 n이 아니라 n - 1을 사용하고 있다는 점에 유의하기 바란다. R에서 기본적으로 계산하는 분산과 표준 편차는 전체 데이터 중 일부를 샘플로 추출한 뒤 이에 대해 분산과 표준 편차를 계산하는 표본 분산과 표본 표준 편차다. 따라서 n - 1을 분모로 사용한다.2
다음 표에 평균, 표본 분산, 표본 표준 편차 계산 함수를 보였다.
|
mean : 평균을 계산한다. |
mean( x, # trim은 데이터를 크기 순서로 나열한 뒤 값이 작은 쪽과 큰 쪽에서 얼마만큼의 데이터를 # 제거한 다음 평균을 계산할지를 (0, 0.5) 사이의 값으로 지정한다. 이렇게 계산한 평균을 # 절사평균(Trimmed Mean)이라고 한다. trim=0, na.rm=FALSE, # 평균 계산 전 NA를 제거할지 여부 ... ) |
|
var : 표본 분산을 계산한다. |
var( x, na.rm=FALSE, ) |
|
sd : 표본 표준 편차를 계산한다. |
sd( x, na.rm=FALSE, ) |
다음은 c(1, 2, 3, 4, 5)의 평균, 표본 분산, 표본 표준 편차를 계산한 예다.
> mean(1:5) [1] 3 > var(1:5) [1] 2.5 > sum((1:5-mean(1:5))^2)/(5-1) # 분모로 n-1이 사용됨을 확인할 수 있음 [1] 2.5 > sd(1:5) [1] 1.581139
2 n-1로 나누는 이유는 위키피디아에서 베셀의 수정(Bessel’s Correction; http://en.wikipedia.org/wiki/Bessel%27s_correction)을 참고하기 바란다.