결측치의 처리
데이터에 결측치NA가 있는 경우 값이 존재하지 않으므로 해당 변숫값을 사용한 계산을 수행할 수 없다. 결측치가 있는 경우 rpart(10.3.2절 참조)는 NA를 대신하는 변수인 surrogate 변수를 사용하여 결측치 문제를 해결한다. 반면 랜덤 포레스트(10.3.4절 참조) 모델은 곧바로 에러를 발생시킨다. 이 경우 NA를 다른 값으로 대체해주는 randomForest::rfImpute( ) 함수를 사용할 수 있다.
이처럼 데이터에 결측치가 있는 경우 모델 자체에서 제공하는 알고리즘을 사용하거나 결측치를 다른 값으로 대체해주는 함수를 활용하게 된다. 결측치를 다른 값으로 바꾸는 것을 대체(대치)imputation라 한다.
이 절에서는 결측치를 대치하는 일반적인 방법에 대해서 살펴본다.
|
complete.cases : 관측값에 결측치가 없는지를 테스트한다. |
complete.cases( ... # 벡터, 행렬 또는 데이터 프레임 ) 반환 값은 관측값에 결측치가 있으면 FALSE, 없으면 TRUE다. |
|
is.na : 결측치인 NA인지 여부를 반환한다. |
is.na( x # 벡터, 리스트 등의 R 객체 ) 반환 값은 NA인 경우 TRUE, NA가 아닌 경우 FALSE다. |
|
DMwR::centralInputation : NA를 가운데 값(central value)으로 대체한다. |
DMwR::centralInputation( ) 반환 값은 NA 값이 가운데 값으로 대체된 데이터 프레임이다. 가운데 값은 각 컬럼에 대해 DMwR::centrlValue( )가 반환하는 값으로 정해진다. centralValue( )는 숫자의 경우 중앙값, 팩터의 경우 최빈값이다. |
|
DMwR::knnImputation : NA를 k 최근 이웃 분류 알고리즘을 사용해 대체한다. |
DMwR::knnImputation( data, # 데이터 프레임 k # k 최근 이웃 분류 알고리즘에서 몇 개의 이웃을 볼 것인지를 지정 ) 반환 값은 k 최근 이웃 분류 알고리즘을 사용해 NA를 대체한 데이터 프레임이다. NA를 대체하는 값은 k 최근 이웃 분류 알고리즘을 사용해 찾은 k개 주변 이웃의 값을 주변 이웃까지의 거리를 고려해 가중 평균한 값이다. |
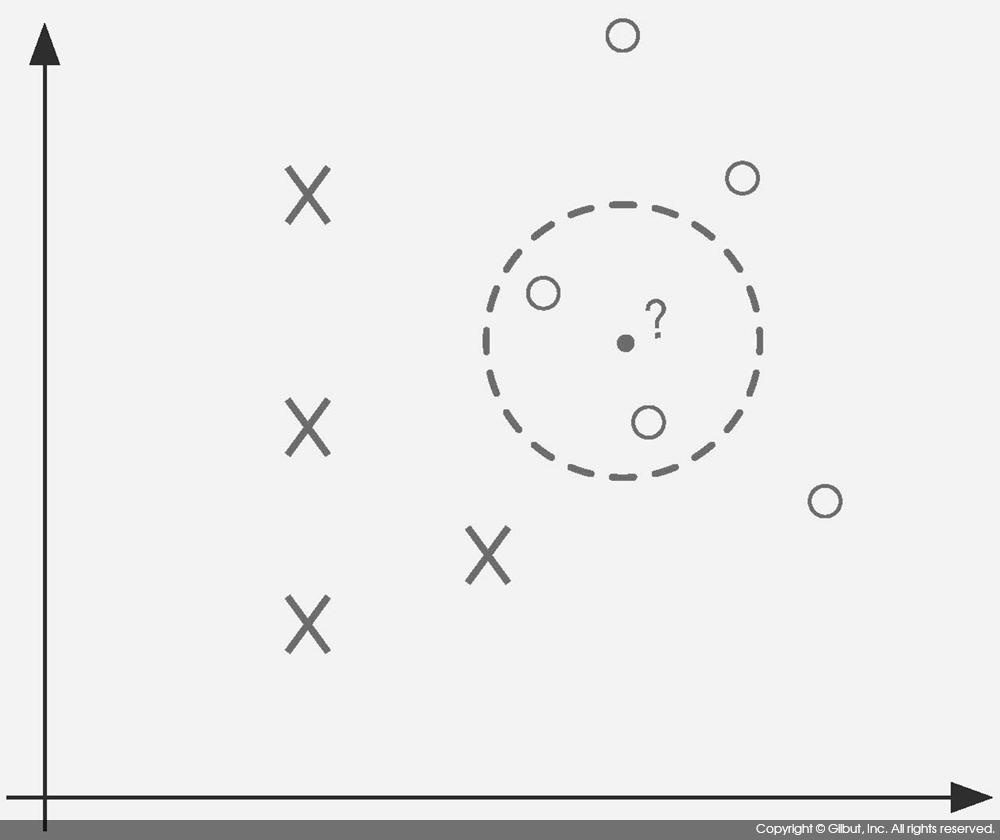
k 최근 이웃 분류 알고리즘은 예측하고자 하는 데이터로부터 가장 가까운 k개 이웃을 찾은 뒤 이들 이웃으로부터 예측하고자 하는 데이터의 분류를 정하는 방법이다. 예를 들어, 그림 9-11을 보자. 그림에 표시된 X, O는 각 점의 분류를 의미한다. ?로 표시된 점은 분류를 예측해야 하는 점이다. k=2인 경우 ?로부터 가장 가까운 점은 점선으로 표시한 원 안에 있는 O 점 두 개다. 따라서 ?의 분류는 k 최근 이웃 알고리즘에서 O로 예측한다.