ROC 커브
많은 기계 학습 모델은 그 내부에서 결과가 Y일 확률 또는 점수를 계산한다. 그리고 점수가 특정 기준을 넘으면 Y로, 기준을 넘지 않으면 N으로 예측값을 출력한다. 예를 들어, 표 9-13과 같이 각 관측값에 대한 점수가 주어졌다고 하자.
|
관측값 번호 |
점수 |
|
#3 |
0.937 |
|
#7 |
0.830 |
|
#2 |
0.738 |
|
#15 |
0.720 |
|
#6 |
0.603 |
표 9-13에서 점수의 기준값을 0.7로 놓으면 #3, #7, #2, #15는 Y로 #6은 N으로 예측된다. 기준값을 0.8로 하면 #3, #7만 Y로 예측된다.
ROC 커브는 점수 기준을 달리할 때 TP Rate와 FP Rate가 어떻게 달라지는지 그래프로 표시한 것이다. 표 9-13의 데이터에 실제 분류를 추가하면 표 9-14가 된다.
|
관측값 번호 |
점수 |
실제 분류 |
|
#3 |
0.937 |
Y |
|
#7 |
0.830 |
Y |
|
#2 |
0.738 |
N |
|
#15 |
0.720 |
N |
|
#6 |
0.603 |
Y |
표 9-14와 같은 데이터가 있을 때 예측을 Y로 판단하는 기준값이 관측값 #3과 같다면 TP Rate는 1/3, FP Rate는 0이다. 기준값이 #7과 같았다면 TP Rate는 2/3, FP Rate는 0이다. 이를 정리하면 표 9-15와 같다.
|
기준값 |
TP Rate |
FP Rate |
|
0.937 |
1/3 |
0 |
|
0.830 |
2/3 |
0 |
|
0.738 |
2/3 |
1/2 |
|
0.720 |
2/3 |
2/2 |
|
0.603 |
3/3 |
2/2 |
표 9-15를 X 축을 FP Rate, Y축을 TP Rate로 한 좌표 평면에 그린 것이 그림 9-18에 보인 ROC 커브다.
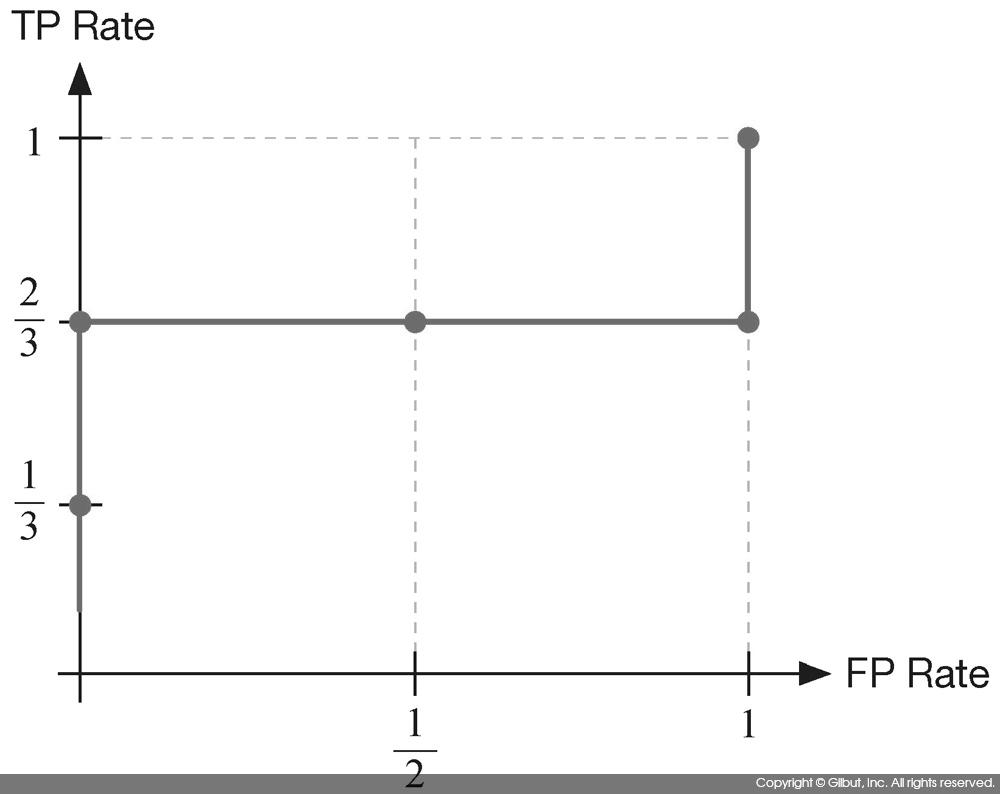
이처럼 ROC 커브는 FP Rate 대비 TP Rate의 변화를 뜻한다. 따라서 그림 9-19에 보인 것처럼 TP Rate가 1로 한 번에 올라간 뒤 FP Rate가 뒤따라 증가하는 형태가 가장 이상적이다. 이런 형태는 실제로 Y인 결과에 높은 점수를 주는 모델을 뜻한다.