교차 검증(Cross Validation)
데이터의 어느 정도를 훈련 데이터로 하고, 또 어느 정도를 테스트 데이터로 할지는 결정하기 쉽지 않다. 만약 훈련 데이터의 크기를 너무 작게 한다면 모델링에 사용할 데이터가 적어 실제 도달 가능한 성능보다 낮은 성능의 모델이 만들어질 것이다. 이 경우 테스트 데이터로부터 추정한 성능은 실제보다 낮은 값이 된다. 반대로 훈련 데이터의 크기를 너무 크게 한다면 테스트 데이터의 크기가 작아진다. 이 경우 적은 수의 데이터로만 테스트를 수행하게 되어 계산한 성능의 신뢰도가 낮아진다.
훈련 데이터와 테스트 데이터의 분리 방법도 문제가 된다. 만약 우연히 테스트 데이터에서의 성능이 잘 나오도록 훈련 데이터와 테스트 데이터를 분리한다면 적절치 않은 성능 평가가 될 것이다. 반대의 경우도 마찬가지다.
이러한 문제들을 개선하는 한 가지 방법이 교차 검증이다. 교차 검증은 데이터를 훈련 데이터와 검증 데이터Validation Data로 나누어 모델링 및 평가하는 작업을 K회 반복하는 것으로, 이를 K겹 교차 검증K-fold Cross Validation이라 한다. 보통 K 값은 10으로 지정한다. 다음은 10겹 교차 검증10-fold Cross Validation의 수행 단계다.
1. 데이터를 10등분하여 D1, D2, …, D10으로 분할한다.
2. K 값을 1로 초기화한다.
3. DK를 검증 데이터, 그 외의 데이터를 훈련 데이터로 하여 모델을 생성한다.
4. 검증 데이터 DK를 사용해 모델의 성능을 평가한다. 평가된 모델의 성능을 PK라 한다.
5. K가 9 이하인 값이면 K = K + 1을 하고 3단계로 간다. 만약 K = 10이면 종료한다.
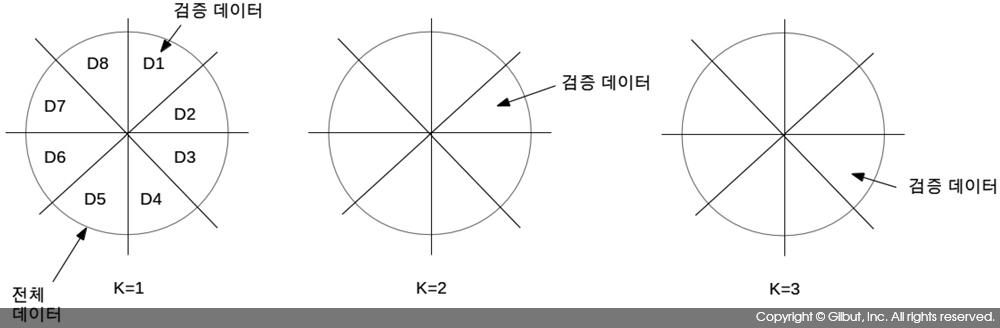
예를 들어, K=1이라면 D1이 검증 데이터, D2, D3, …, D10이 훈련 데이터로 사용된다. 만약 K=2라면 D2가 검증 데이터, D1, D3, D4, …, D10이 훈련 데이터로 사용된다. 이처럼 각 K마다 DK를 검증 데이터로, 나머지를 훈련 데이터로 사용한다. 최종적으로 K=10일 경우 D10이 검증 데이터, D1, D2, D3, …, D9가 훈련 데이터로 사용된다.
이 단계를 거치면 모델의 성능이 P1, P2, …, P10으로 구해지며, 최종 성능은 이들의 산술 평균으로 정할 수 있다.
그림 9-26에 8겹 교차 검증의 예를 보였다. 그림으로부터 K=4, 5, 6, 7, 8일 때의 검증 데이터 역시 쉽게 짐작할 수 있을 것이다.
경우에 따라서는 평가의 정확도를 더 높이기 위해 K겹 교차 검증을 R회 반복할 수 있다. 예를 들면, 10겹 교차 검증을 3회 반복하는 식이다.
교차 검증을 통해 최선의 모델을 만드는 방법을 결정하고 나면 전체 데이터를 사용해 모델을 만든 뒤 이 모델을 결과로 제출한다.