02 | 다항 로지스틱 회귀 분석
예측하고자 하는 분류가 두 개가 아니라 여러 개가 될 수 있는 경우 다항 로지스틱 회귀 분석Multinomial Logistic Regression을 사용한다. 이 방법의 기본 아이디어는 로지스틱 회귀 분석을 확장하는 것이다. 이 절에서는 위키피디아에 설명된 독립 바이너리 회귀의 집합에 따라 모델을 설명한다.[3]
분류 K를 기준으로 하여 데이터가 각 분류에 속할 확률을 βiXi로 놓는다.

양변을 e의 지수로 하고 정리하면 다음과 같다.

확률의 합은 1이므로 위 식의 좌변과 우변을 모두 합하면 다음과 같다.
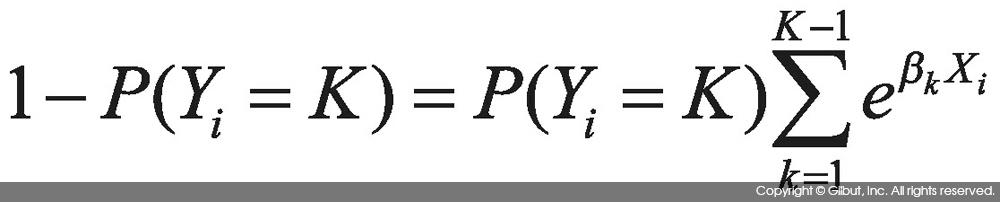
이를 정리하면 P(Yi = K를 다음과 같이 구할 수 있다.
최종적으로 i < K인 경우는 P(Yi = i)는 다음과 같다.
R에서는 nnet::multinom( )을 사용해 다항 로지스틱 회귀 모델을 작성할 수 있다.
|
nnet::multinom : 다항 로지스틱 회귀 모델을 생성한다. |
nnet::multinom( formula, # 모델 포뮬러 data, # 포뮬러를 적용할 데이터 ) 반환 값은 nnet 객체다. |
|
fitted : 모델에 의해 훈련 데이터가 어떻게 적합(fit)되었는지 보인다. |
fitted(
object # 모델
)
기계 학습 모델은 훈련 데이터에 대한 분류 예측을 잘 수행하도록 파라미터를 수정해가면서 만들어진다. 이를 모델이 훈련 데이터에 적합된다고 말한다. fitted( )의 반환 값은 모델이 훈련 데이터에 어떻게 적합되었는지 보여주는 값들이다. |
|
predict.multinom : 다항 로지스틱 회귀 모델을 사용한 예측을 수행한다. |
predict.multinom( object, # multinom() 함수로 생성한 nnet 객체 newdata, # 예측을 수행할 데이터 # 예측 결과의 유형. class는 분류를, probs는 각 분류일 확률을 반환한다. 기본값은 class다. type=c("class", "probs") ) 반환 값은 예측 결과다. |