노드를 나누는 기준
그림 10-1에서 원, 삼각형, 사각형과 같은 도형이 그려진 곳을 노드Node라 한다. 노드 중 분류의 시작점에 해당하는 최상단에 위치한 노드를 뿌리 노드(루트 노드)Root Node, 더 이상 자식 노드가 없는 제일 하단의 노드를 잎사귀 노드(리프 노드)Leaf Node라 한다.
의사 결정 나무는 각 노드마다 질문을 던지고 그 응답에 따라 가지를 쳐서 데이터를 분리한다. 데이터가 얼마나 잘 분리되었는지는 불순도impurity라는 기준으로 평가하며, 가장 좋은 질문은 한 노드의 데이터를 두 개의 자식 노드로 분리했을 때 자식 노드들의 불순도가 가장 낮아지는 질문이다.
불순도는 노드에 여러 분류가 섞여 있을수록 높다. 반면 하나의 분류만 있다면 낮다. 예를 들어, 그림 10-1의 뿌리 노드에는 원, 삼각형, 사각형, 검은색 사각형, 검은색 원이 섞여 있어 불순도가 높지만, 가장 오른쪽 아래 노드에는 흰색 원만 두 개가 있어 불순도가 낮다.
불순도 함수 f가 있다고 할 때 노드 A의 불순도 I(A)는 다음과 같이 정의한다.
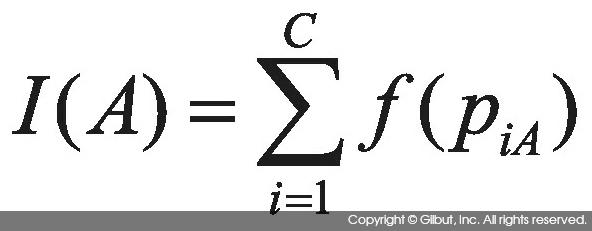
이 식에서 C는 분류의 개수며, piA는 노드 A에 속한 분류 i인 표본의 비율이다.
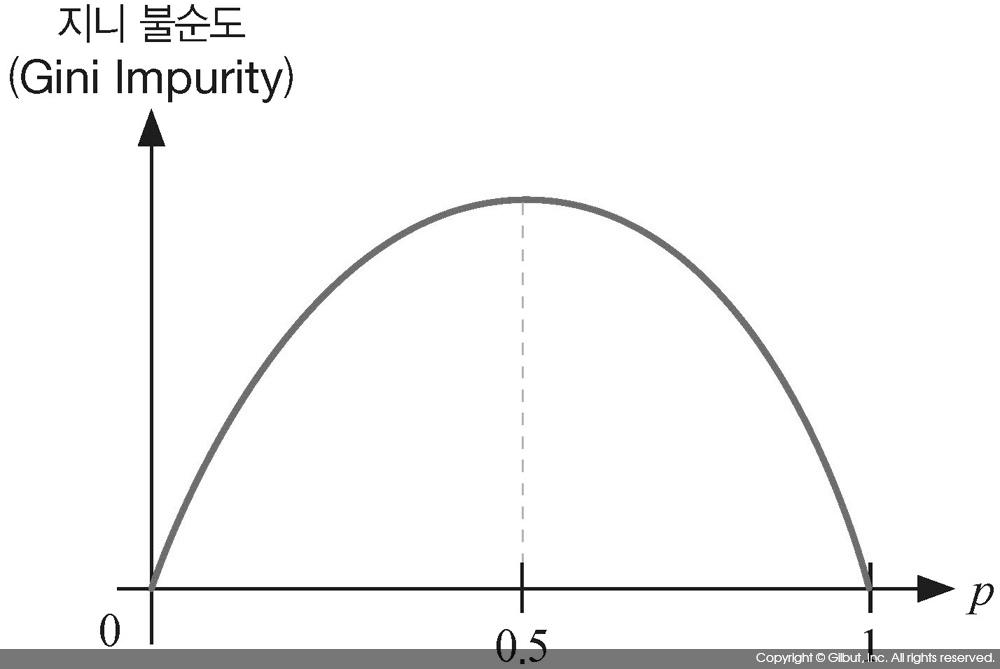
가장 흔히 사용하는 불순도 함수는 지니 불순도Gini Impurity로, 다음과 같이 정의된다.[5]
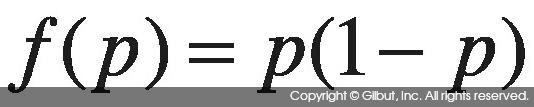
지니 불순도는 p=0 또는 p=1일 때 0이며 p=1/2일 때 가장 큰 값을 가지는 포물선이다. 지니 불순도를 식 10-2와 연관해서 생각해보면 노드에 특정 분류 i만 있거나 특정 분류 i가 전혀 없을 때 I(A)가 작은 값을 가지며, 여러 분류가 섞여 있을 때 큰 값을 갖게 된다. 그림 10-2에 지니 불순도 곡선을 보였다.