변수 중요도 평가
‘9.2.3 변수 선택’ 절에서는 모델링에 사용할 변수를 선택하는 방법에 대해 살펴봤다. randomForest( ) 역시 변수의 중요도를 평가하고 모델링에 사용할 변수를 선택하는 데 사용할 수 있다. randomForest( )의 변수 중요도는 변수가 정확도와 노드 불순도 개선에 얼마만큼 기여하는지로 측정된다. 이렇게 구한 변수 중요도는 다른 모델(예를 들면, 선형 회귀)에 사용할 변수를 선택하는 데 사용할 수 있다. 즉, 이 방법은 변수 선택 방법 중 필터 방법이다.
변수의 중요도를 알아보려면 모델 작성 시 randomForest( )에 importance=TRUE를 지정한다. 그런 다음 importance( ), varImpPlot( )을 사용해 결과를 출력한다.
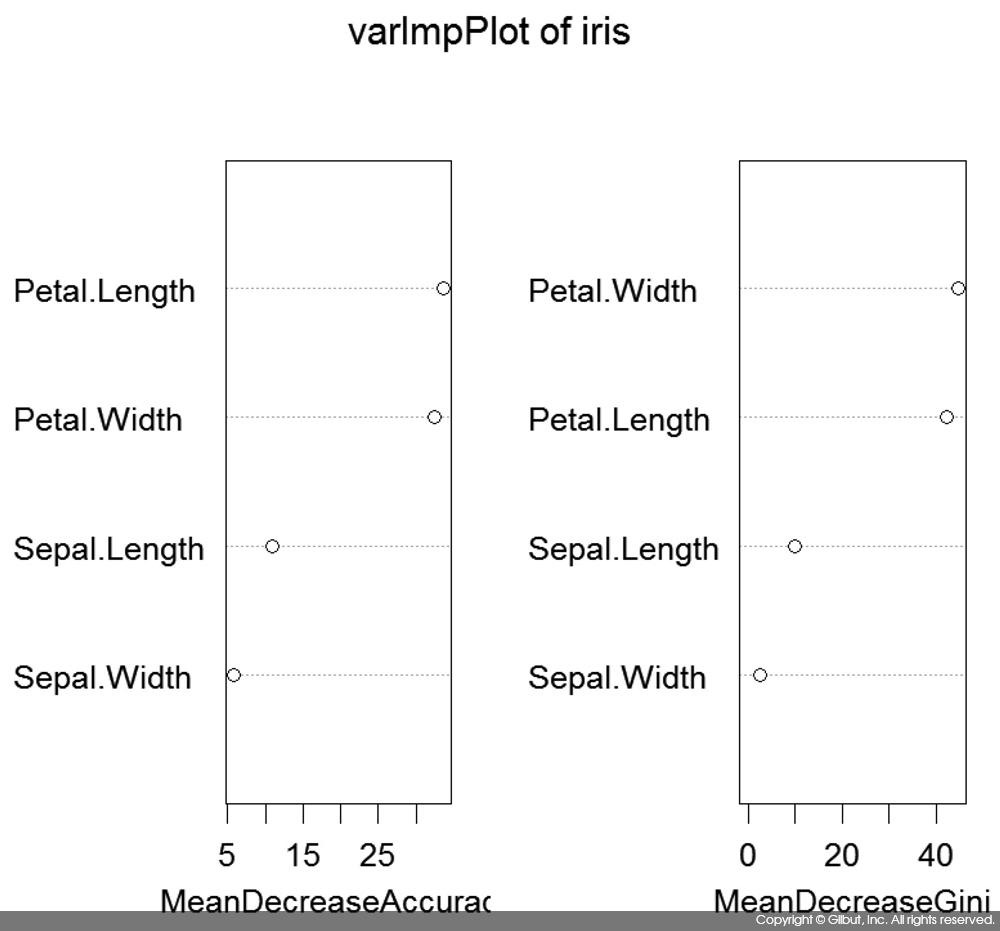
다음은 iris에 대한 랜덤 포레스트로부터 변수 중요도를 평가한 결과이다. 정확도MeanDecreaseAccuracy에서는 Petal.Length, Petal.Width, Sepal.Length, Sepal.Width 순으로 변수가 중요함을 알 수 있다. 노드 불순도 개선MeanDecreaseGini에서는 Petal.Width, Petal.Length, Sepal.Length, Sepal.Width 순으로 중요했다. 다수의 의사 결정 나무로부터 변수가 정확도와 노드 불순도 개선에 기여하는 측면을 평가하므로 평균(Mean)이 언급되어 있다.
> m <- randomForest(Species ~., data=iris, importance=TRUE) > importance(m) setosa versicolor virginica MeanDecreaseAccuracy MeanDecreaseGini Sepal.Length 6.622012 8.534426 7.485710 10.923173 9.920924 Sepal.Width 4.626843 2.962443 4.699581 5.799664 2.392394 Petal.Length 23.070189 32.907859 27.733675 33.648923 42.229501 Petal.Width 21.420105 32.365774 28.948582 32.420192 44.710727
varImpPlot( )을 사용해 이를 그림으로 좀 더 쉽게 알아볼 수 있다.
> varImpPlot(m, main="varImpPlot of iris")
정규화 랜덤 포레스트RRF, Regularized Random Forest[9]는 랜덤 포레스트를 개선한 변수 선택 방법으로, 부모 노드에서 가지를 나눌 때 사용한 변수와 유사한 변수로 자식 노드에서 가지를 나눌 경우 해당 변수에 패널티를 부여한다. 이 방식은 랜덤 포레스트를 직접 변수 선택에 사용하는 경우에 비해 좋은 변수들을 선택해주는 것으로 알려져 있다. 관심 있는 독자는 RRF 패키지[10]를 사용해보기 바란다.