weighting 함수 중 가장 많이 사용되는 함수는 TF-IDF[21]다. TF-IDF 값이 크면 해당 단어가 문서를 더 잘 기술한다는 의미다.
TF는 Term Frequency의 약어로, 단어의 출현 횟수를 뜻한다. 예를 들어, computer에 관련된 문서를 찾는 상황을 가정해보자. computer라는 단어가 전혀 안 나오거나 한 번 나온 문서보다 computer라는 단어가 열 번 나온 문서가 computer에 대해 더 많이 그리고 자세히 기술하고 있음을 쉽게 짐작할 수 있다. 이런 이유로 단어의 출현 횟수는 문서를 설명하는 주요한 특징이 된다.
TF를 계산하는 방법은 여러 가지가 될 수 있다. 첫 번째는 어떤 단어가 그 문서에 출현하는지 여부를 TRUE, FALSE로 지정하는 방법이다. 이 방법은 단어가 여러 번 출현한 것과 한 번 출현한 것을 구분하지 않는다.
두 번째 방법은 로그 함수를 사용한다. 로그를 사용하면 단어의 출현 빈도가 수회 내에서 차이나는 것은 크게 TF에 반영되고, 수십 회 등의 큰 값에서 차이나는 것은 TF에 큰 영향을 주지 않는다.5 따라서 약간의 출현에는 민감하되 단어가 많이 나온다고 너무 가중치를 크게 주지 않는 값을 구할 수 있게 된다. 식 10-10에 로그를 사용한 TF를 보였다. 식에서 f(t, d)는 단어 t가 문서 d에 출현한 횟수다. 식에서 1을 더해준 이유는 로그 함수가 0에 대해서는 정의되어 있지 않기 때문이다.
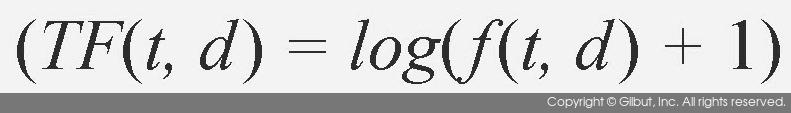
TF를 계산할 때 고려할 또 다른 내용은 문서가 길어지면 모든 단어의 출현 횟수가 저절로 커진다는 점이다. 따라서 문서의 길이로 정규화를 해주지 않으면 긴 문서를 선호하는 모델을 만들게 된다. 정규화를 적용한 식을 10-11에 보였다. 식에서 분모는 모든 단어 중 문서에서 출현 횟수가 가장 많았던 단어의 출현 횟수다. 이 부분이 정규화에 해당한다. 분자는 출현 횟수에 0.5를 곱한 값이며 모든 단어에 0.5의 기본적인 출현 횟수를 부여했다. 이처럼 0.5를 TF에 기본으로 주는 이유는 어떤 단어가 특정 문서에 전혀 나오지 않았다고 해도 탐색 대상에서 완전히 빼버리지는 않기 위해서다. 예를 들어, computer라는 단어가 한 번도 문서에 나오지 않았다고 해도 그 문서가 여전히 컴퓨터에 대한 글일 수 있다.
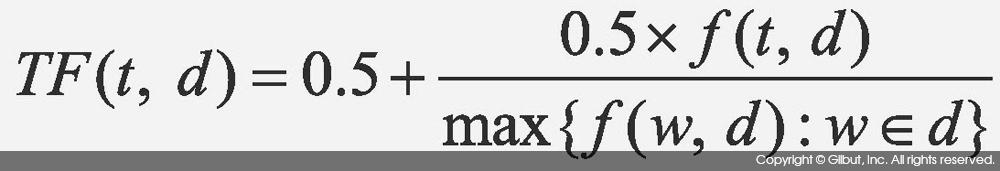
IDF는 Inverse Document Frequency의 약어로, 단어가 출현한 문서 수의 역수다. 예를 들어, 컴퓨터 그래픽에 대한 문서를 찾는 모델을 만든다고 가정해보자. 이 분류 문제에 사용할 주요 단어는 computer와 graphics다. 그런데 마침 주어진 문서 집합이 모두 컴퓨터 분야의 문서라면 computer는 모든 문서에서 출현할 것이다. 반면 graphics는 컴퓨터 그래픽에 대한 문서에서만 출현할 것이다. 따라서 computer와 graphics라는 두 단어를 봤을 때 모든 문서에서 출현한 computer는 문서를 분류하는 데 효용이 없지만 일부 문서에서만 출현하는 graphics는 큰 도움이 된다. IDF는 이를 고려한 값이다. 식 10-12에서 D는 전체 문서 집합이며, d는 개별 문서를 뜻한다. 분자의 N은 전체 문서의 수며, 분모는 단어 t가 포함된 문서의 수다.
TF-IDF는 TF와 IDF의 곱이다. 식 10-13에 TF-IDF를 보였다.
문서의 특징을 나타낼 때 식 10-13을 그대로 써야 하는 것은 아니다. 경우에 따라서는 IDF를 생략하고 TF만 사용할 수도 있으며 TF를 계산하는 방법도 여러 가지다. SMART(System for the Mechanical Analysis and Retrieval of Text)[22]는 TF, IDF를 사용한 계산을 수행하는 다양한 조합을 나타낸다. tm에서는 weightSMART가 이를 지원한다. SMART의 정확한 이해를 위해서는 벡터 스페이스 모델을 사용한 정보 검색에 대한 이해가 필요하다.[23]
5 예를 들어, 밑이 10인 로그에서 log(2)=0.301, log(4)=0.602지만 log(10)=1, log(20)=1.301이다. 로그 함수의 입력이 2에서 4로 두 배가 되면 log를 취한 값 역시 두 배 가까이 차이나지만 10이 20으로 두 배가 되어도 1.3배밖에 되지 않는다.