03 | 데이터 탐색
모델을 작성하기 전에 데이터가 어떤 모습을 하고 있는지 살펴보면 모델을 세울 방법에 관한 많은 힌트를 얻을 수 있다. 또, 데이터를 불러들일 때 혹시 에러가 있지는 않았는지도 이 단계에서 알 수 있게 된다. 이 단계에서는 간단하게 summary( )를 사용해 데이터의 분포를 살펴볼 수도 있고, 데이터를 그림으로 그려서 표현해볼 수도 있다.
Hmisc 패키지에는 summary( )에 포뮬러를 지정해 데이터의 요약 정보를 얻을 수 있는 기능이 있다. survived가 pclass, sex, age 등의 값에 따라 어떻게 달라지는지 요약 정보를 살펴보자.
> library(Hmisc) > # 교차 검증의 첫 번째 분할에서의 훈련 데이터를 사용한 데이터 탐색 > data <- create_ten_fold_cv()[[1]]$train > # method="reverse"는 종속 변수 survived에 따라 독립 변수들을 분할하여 보여줌 > summary(survived ~ pclass + sex + age + sibsp + parch + fare + embarked, data=data, + method="reverse") Descriptive Statistics by survived +------------+----+-----------------------+-----------------------+ | |N |dead |survived | | | |(N=656) |(N=405) | +------------+----+-----------------------+-----------------------+ |pclass : 1 |1061| 15% ( 99) | 39% (159) | +------------+----+-----------------------+-----------------------+ | 2 | | 20% (130) | 24% ( 96) | +------------+----+-----------------------+-----------------------+ | 3 | | 65% (427) | 37% (150) | +------------+----+-----------------------+-----------------------+ |sex : male |1061| 85% (555) | 32% (131) | +------------+----+-----------------------+-----------------------+ |age | 850| 21/28/39 | 20/27/39 | +------------+----+-----------------------+-----------------------+ |sibsp : 0 |1061| 72% (473) | 62% (253) | +------------+----+-----------------------+-----------------------+ | 1 | | 19% (123) | 32% (128) | +------------+----+-----------------------+-----------------------+ | 2 | | 3% ( 20) | 4% ( 16) | +------------+----+-----------------------+-----------------------+ | 3 | | 2% ( 10) | 1% ( 6) | +------------+----+-----------------------+-----------------------+ | 4 | | 2% ( 16) | 0% ( 2) | +------------+----+-----------------------+-----------------------+ | 5 | | 1% ( 6) | 0% ( 0) | +------------+----+-----------------------+-----------------------+ | 8 | | 1% ( 8) | 0% ( 0) | +------------+----+-----------------------+-----------------------+ |parch : 0 |1061| 83% (547) | 67% (270) | +------------+----+-----------------------+-----------------------+ | 1 | | 7% ( 48) | 21% ( 84) | +------------+----+-----------------------+-----------------------+ | 2 | | 7% ( 47) | 11% ( 46) | +------------+----+-----------------------+-----------------------+ | 3 | | 0% ( 3) | 1% ( 4) | +------------+----+-----------------------+-----------------------+ | 4 | | 1% ( 4) | 0% ( 0) | +------------+----+-----------------------+-----------------------+ | 5 | | 0% ( 3) | 0% ( 1) | +------------+----+-----------------------+-----------------------+ | 6 | | 0% ( 2) | 0% ( 0) | +------------+----+-----------------------+-----------------------+ | 9 | | 0% ( 2) | 0% ( 0) | +------------+----+-----------------------+-----------------------+ |fare |1061| 7.8542/10.5000/26.0000|10.5000/26.0000/57.0000| +------------+----+-----------------------+-----------------------+ |embarked : C|1059| 16% (103) | 30% (120) | +------------+----+-----------------------+-----------------------+ | Q | | 9% ( 58) | 9% ( 37) | +------------+----+-----------------------+-----------------------+ | S | | 75% (495) | 61% (246) | +------------+----+-----------------------+-----------------------+
표를 통해 pclass, sex 등 각 변숫값에 따라 생존율의 분포가 어떻게 달라지는지 볼 수 있다.
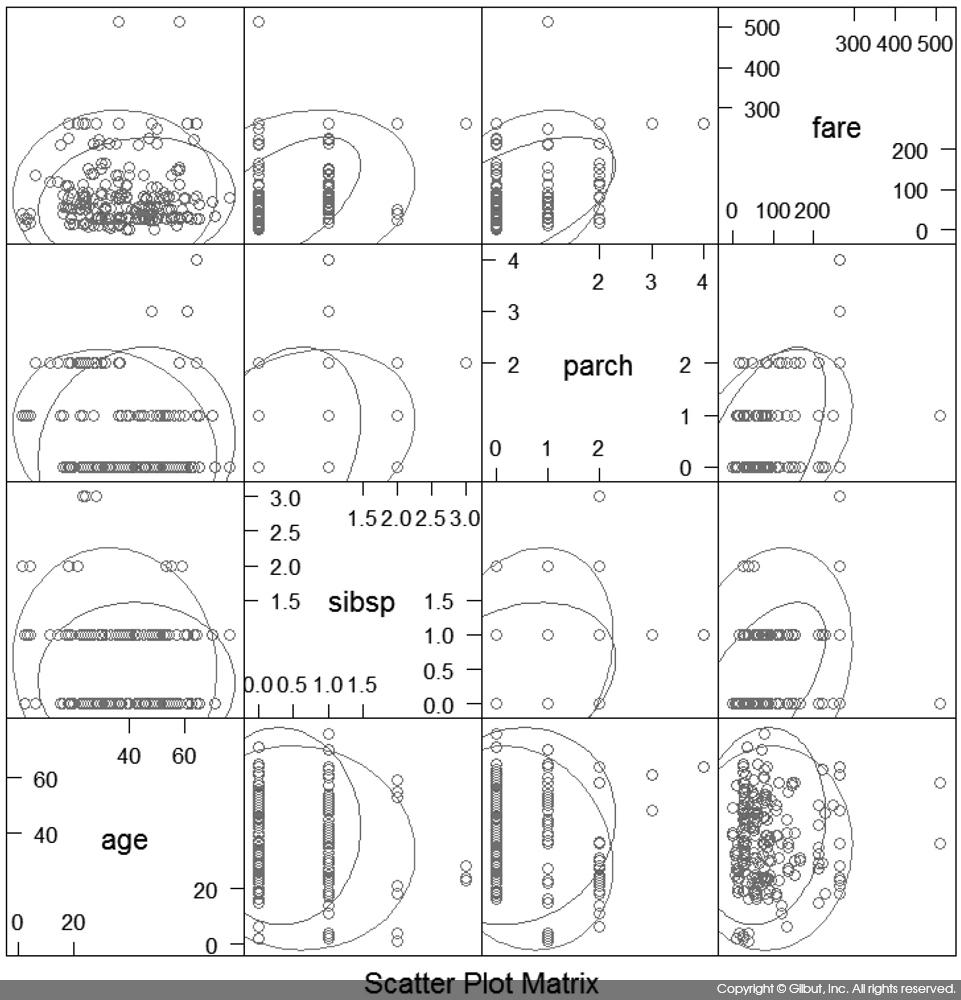
이번에는 caret::featurePlot( )을 사용해 데이터를 시각화해보자. 예측 대상이 되는 생존 또는 사망 여부를 Y, 예측 변수를 X로 해서 featurePlot( )을 호출하는 것이 목표다. featurePlot( ) 사용 시 NA 값이 있으면, 차트가 제대로 그려지지 않으므로 NA부터 제거해야 한다. 이때 데이터 프레임의 각 행에 NA 값이 하나도 없는지 여부를 테스트해주는 complete.cases( )를 사용한다. 그런 다음 featurePlot( )의 X에는 팩터를 지정할 수 없으므로 숫자numeric 컬럼만 선택하여 X에 지정한다.
> data <- create_ten_fold_cv()[[1]]$train > data.complete <- data[complete.cases(data), ] > featurePlot( + data.complete[, + sapply(names(data.complete), + function(n) { is.numeric(data.complete [, n]) })], + data.complete [, c("survived")], + "ellipse")
위의 코드에서 sapply( ) 부분은 다음과 같이 동작한다. names(data.complete)는 data.complete의 컬럼명들(pclass, survived, name, sex, age, …, embarked 등)을 반환한다. sapply( )는 이 각각의 이름을 function( )에 n이라는 이름으로 넘긴다. 호출된 함수는 data.complete에서 해당 컬럼이 숫자형 데이터인지를 is.numeric( )으로 테스트해 반환한다. 따라서 sapply( )의 최종 결과는 TRUE 또는 FALSE가 저장된 벡터다. 이 결과가 data.complete[, sapply( )] 형태로 호출되므로 숫자 데이터 타입을 저장한 컬럼만 선택된다.
그림 11-2에 featurePlot( )의 결과를 보였다.