# average length of the words in the text
df_train["mean_word_len"] = df_train["comment_text"].apply(
lambda x: np.mean([len(w) for w in str(x).split()])
)
df_test["mean_word_len"] = df_test["comment_text"].apply(
lambda x: np.mean([len(w) for w in str(x).split()])
)
df_train.describe()
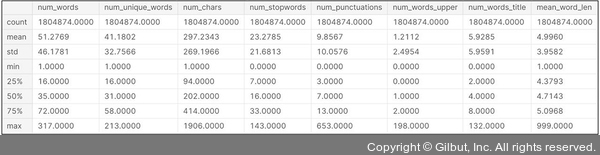
▲ 그림 7-8 텍스트 통계량 결과