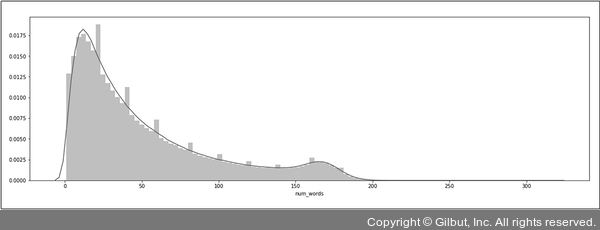
▲ 그림 7-9 num_words 텍스트 통계량
Note ≣ | 토큰의 길이
참고로 앞서 이야기한 길이 값은 텍스트를 토큰화(Tokenization)하는 방식에 따라 조금씩 달라질 수 있습니다. 일반적으로 텍스트 데이터는 그 자체를 모델 학습에 사용하기보다는, 어떤 특정 id 값을 가진 토큰으로 치환한 뒤에 사용하는 편입니다. 이때 치환 방식을 띄어쓰기로 구분된 단어 단위로 할 수도 있고, 글자 단위로 할 수도 있고, 또는 사전에 형태소 분석을 거친 뒤 의미 단위의 토큰으로 쪼개서 사용할 수도 있습니다. 이 중 어떤 것을 선택하느냐에 따라 텍스트를 표현할 수 있는 토큰의 길이가 달라지므로, 각 방법에 맞는 길이를 찾아야 합니다. 앞서 소개한 num_words는 띄어쓰기로 텍스트를 구분한 토큰화와 같다고 볼 수 있습니다.